딥러닝 신경망 - (4) 신경망 연산
이번 글은 딥러닝 연구를 위한 신경망 네 번째 글인 신경망 연산을 이어서 다루도록 하겠습니다.
기본적인 자료는 프랑소와 솔레가 저술한 ‘케라스 창시자에게 배우는 딥러닝(길벗)’ 서적의 내용을 토대로 따왔으며, 제가 직접 그린 이미지도 있지만 책의 이미지도 일부 따왔음을 먼저 알려드립니다. 이번 글은 상기 서적의 2장을 다루었으나, 책의 내용을 참고하여 제 기준에서 나름대로 정리한 내용입니다. 너무 많은 내용을 자세히 설명하면 저작권에 문제가 될 소지가 있으므로 구체적으로는 다루지 않고 대략적으로만 다루니 양해 바랍니다.
본문에 있는 코드 중 일부는 해당 책의 코드이고, 일부는 제가 임의로 작성한 코드이니 역시 참고 바랍니다.
신경망 연산
앞서 세 번째 글에서도 언급했던 MNIST 모델에 대한 예제 코드는 다음과 같았습니다.
from keras.datasets import mnist
from keras import models, layers
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28*28,)))
network.add(layers.Dense(10, activation='softmax'))
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
train_images = train_images.reshape((60000, 28*28))
train_images = train_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
network.fit(train_images, train_labels, epochs=5, batch_size=128)그리고 지난 번 글에서는 layers.Dense()의 relu 함수까지 다루었습니다.
relu 함수를 간단히 복습하면 다음과 같습니다.
- 먼저 28*28 사이즈의 이미지를 1차원 벡터로 풀어서 784개로 입력값을 받도록 하였고
- 512개의 은닉 유닛을 설정하였습니다.
- 그리하여 점곱(dot operation) 연산에 의하여 (784, 512) 형태의 출력이 생성됩니다.
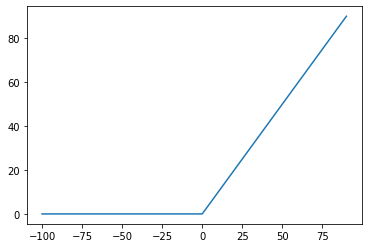
- 생성된 출력은 relu 함수를 사용하며, 이 때 가중치(W)와 편향(B) 값을 자동으로 조절하여 0보다 작은 값은 0으로 치환됩니다.
output = relu(dot(W, input) + b)이제 다음 신경망을 추가하는 순서로 이어지며, layers.Dense() 메소드를 사용하여softmax 활성화 함수를 사용하는 순서로 이어집니다.
Softmax
softmax 함수는 입력값에 대한 출력을 0과 1 사이 값으로 정규화를 수행하는 함수입니다. 하지만 출력값을 단순히 한 개의 값으로 설정하는 것이 아니라, 첫 번째 인자의 값을 가지고 몇 개의 값으로 나타낼 것인지를 결정합니다.
위 예제에 따르면 첫 번째 인자의 값은 10입니다. 이는 즉 softmax 함수를 사용하여 10차원의 배열을 생성한다는 뜻입니다. 당연히 10차원 배열의 모든 값은 0과 1 사이의 확률 값이 들어가며, 모든 차원의 확률의 합은 1로 나타납니다.
그리하여 softmax 함수를 사용하게 되면 10차원으로 요약된 데이터가 출력값으로 나오며, 이 값을 가지고 입력된 이미지에 대한 결과가 어떤 값인지를 표현합니다.
모델 컴파일
모델 컴파일을 위해서는 세 가지 값이 들어갑니다.
- Optimizer: 훈련 결과를 바탕으로 하여 가중치, 편향을 조절하여 신경망의 내용을 업데이트합니다.
- Loss Function: 손실(Loss)가 어느 정도인지를 측정하여 어떻게 조절해야 하는지를 알려줍니다.
- Metrics: 훈련 및 테스트 과정을 모니터링하는 지표로 사용됩니다.
위 코드에서는 Optimizer로 rmsprop, Loss Function으로 categorical_crossentropy, Metrics로 accuracy를 사용했습니다. 각각에 대해서는 나중에 다시 설명하겠지만, 간단히 요약하자면 앞서 구성한 신경망을 사용해서 연산을 할 경우 해당 결과와 라벨의 값이 일치하는 지를 보고, 일치하지 않을 경우에는 가중치를 조정하여 신경망이 좀 더 올바로 학습할 수 있도록 해 줍니다.
위와 같이 반복하게 되면 실제 라벨 값인 y값과, 훈련으로 통해서 나온 값인 예측값 y_pred를 비교하여 둘 간의 오차를 줄이는 기능을 수행합니다.
책에서는 이러한 가중치 조정을 위해서 변화율, 그래디언트(gradient), 확률적 경사 하강법에 대한 설명이 있으며, 미분 공식을 사용하는 것으로도 표현됩니다. 또한 변화율 계산을 위해서 역전파(Backpropagation) 알고리즘을 사용한다는 부분도 언급되어 있고요. 자세한 설명은 책을 직접 구매하시거나 책에 대한 내용을 그대로 표현한 블로그도 있으므로 해당 부분을 참고하시면 될 것 같습니다.
훈련 데이터의 반복
이제 앞서 모델 컴파일까지 완료되었으니, MNIST 모델의 훈련 데이터를 대입하는 순서로 진행됩니다.
train_images = train_images.reshape((60000, 28*28))
train_images = train_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
network.fit(train_images, train_labels, epochs=5, batch_size=128)train_images, train_labels와 관련된 코드는 모델에 입력할 수 있는 크기로 재배치하고, 0~1 사이의 값으로 나타내기 위한 정규화 과정입니다. 딥러닝에서는 이러한 것을 전처리라고 합니다.
이제 network.fit()을 수행하여 모델에 훈련 데이터를 입력하는 순서로 진행됩니다.
epochs는 훈련 반복을 수행할 회수입니다. 훈련을 많이 할 수록 오차가 줄어들겠지만, 일정 회수 이상이 되면 결과 차이가 거의 없기도 합니다. 또한 한 번의 훈련을 수행하는 데 시간이 오래 걸리기 때문에 몇 회 훈련할 것인지는 직접 입력하여 조절하는 것도 방법이겠죠.
batch_size는 입력할 때 몇 차원의 데이터가 입력되느냐를 나타냅니다. 앞서 첫 번째 신경망 층인 relu 함수에서는 (28*28) 크기의 값이 들어가지만, 그 것은 하나의 차원에 들어가는 입력값을 나타냅니다. 이전 글에서 언급했던 그림 중 점곱(dot operation) 연산을 다시 나타내 보겠습니다.
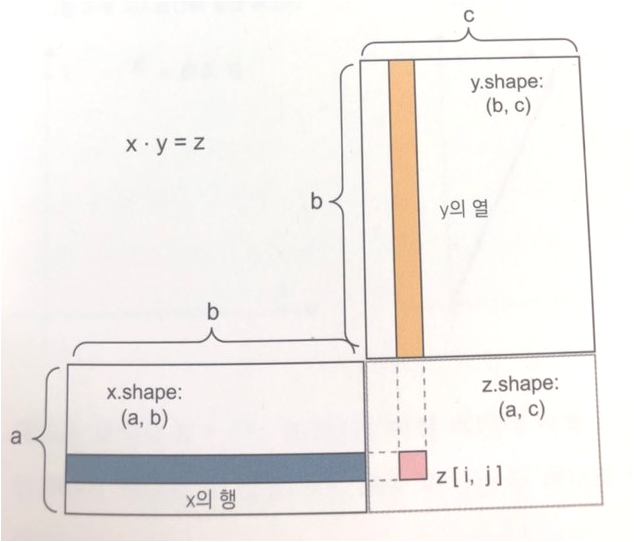
점곱의 x.shape(a,b)에서 a는 (28*28)이 됩니다. 하나의 차원에 784개의 이미지 픽셀 값이 입력되겠죠.
여기에서 b의 값이 바로 batch_size 값이 됩니다. 한 번 학습을 수행할 때 들어가는 값을 배치(batch) 값이라 하며, 이 값은 전체 60000개 값 중에 샘플 값으로 들어가는 값이 됩니다.
가중치 업데이트 역시 한 번의 배치가 끝날 때마다 이루어지며, 총 훈련 데이터는 6만개이기 때문에 한 번의 에포크(epoch) 동안 469번의 배치를 수행하게 되어 가중치 업데이트 역시 469번이 이루어지게 됩니다. 이러한 형태로 반복하게 되면 손실이 많이 줄어들게 되며 보다 정확한 데이터를 나타낼 수 있게 됩니다.
이상 신경망 연산에 대한 부분을 마치겠습니다.
딥러닝에서의 모든 학습은 위와 같은 순서로 이루어지며, 어떤 데이터를 가지고 어떻게 나타내느냐에 따라 사용되는 신경망과 함수도 각각 달라지므로 이에 대한 부분을 하나하나씩 이해하는 순서로 진행될 예정이니 참고 바랍니다.