AWS 머신러닝 Amazon Sagemaker 예제 - Image Classification Fulltraining
이번에 쓸 글은 Amazon Sagemaker 서비스에서 제공하는 머신러닝 예제 프로그램을 같이 실행하는 내용으로, Image-classification-fulltraining을 예제로 하겠습니다.
글을 설명하기 앞서서 말씀드리자면, 본문 첨부된 이미지에 http://onikaze.tistory.com 썸네일이 있는 것을 확인할 수 있는데, 해당 블로그는 제가 그 블로그의 이미지를 무단 도용한 것이 아니라, 그 블로그가 제 예전 블로그였고 이 글 역시 예전 블로그에 썼던 글을 이 곳으로 이관한 것입니다. 이 점 참고 바라겠습니다.
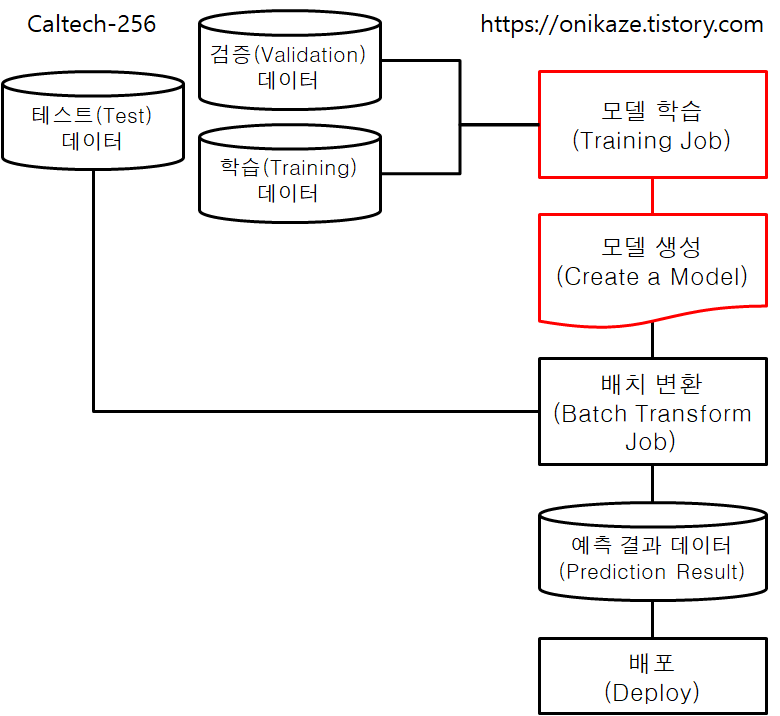
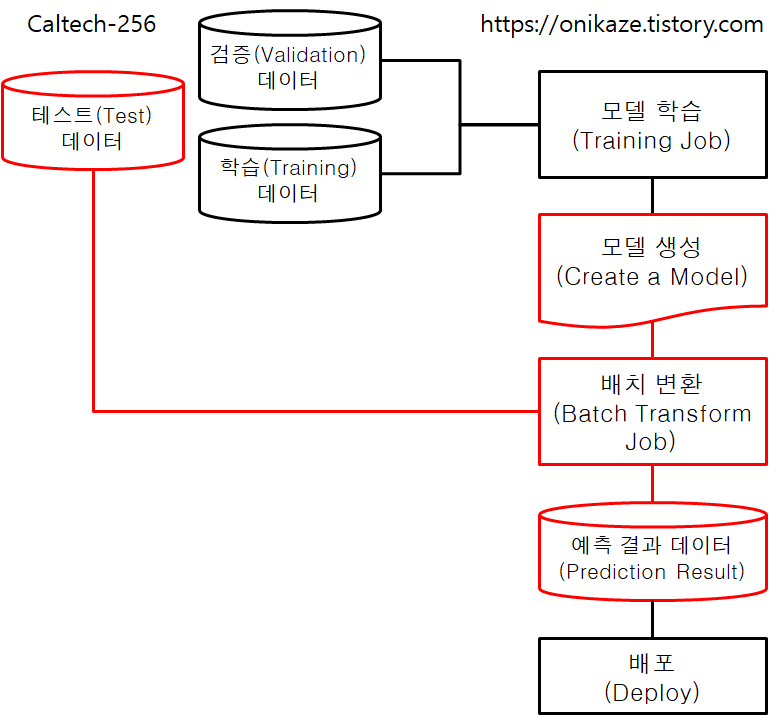
머신러닝에서는 크게 모델 학습(Model Training)과 모델 검증(Model Validation)으로 구분할 수 있지만, Image-classification-fulltraining 예제는 제목 그대로 이미지 분류에 대한 학습을 위한 예제라는 점에서 모델 검증 작업은 이 예제에서는 다루지 않는 대신, 모델 학습 쪽에 중점을 둔 예제로 보시면 되고요. 이것과 관련된 프로세스는 전체 소스코드 및 프로세스를 분석하여 제가 다음과 같이 요약해 봤습니다.
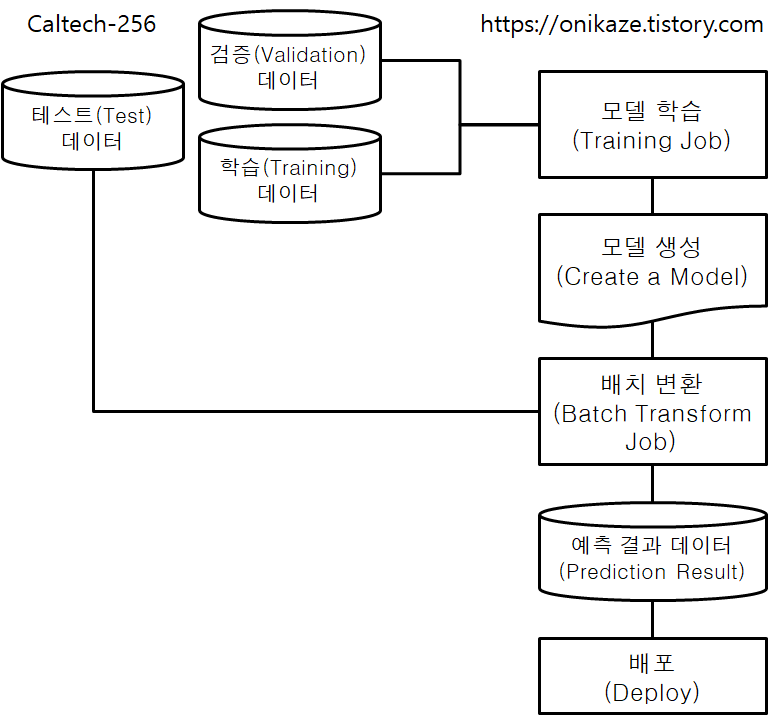
사실 저도 머신러닝은 전문가가 아니라는 점에서 일부 틀린 부분이 있을 수 있습니다만, 일단은 위와 같이 구성해봤으니 참고 정도 하시면 될 것 같습니다.
앞서 작성했던 글과 같이, Sagemaker에서는 Amazon에서 제공하는 다양한 머신러닝 알고리즘이 있습니다. 그 중에서도 아래 화면의 네 번째인 ‘Image-classification-fulltraining.ipynb’ 파일을 사용하는 것으로 하겠습니다.
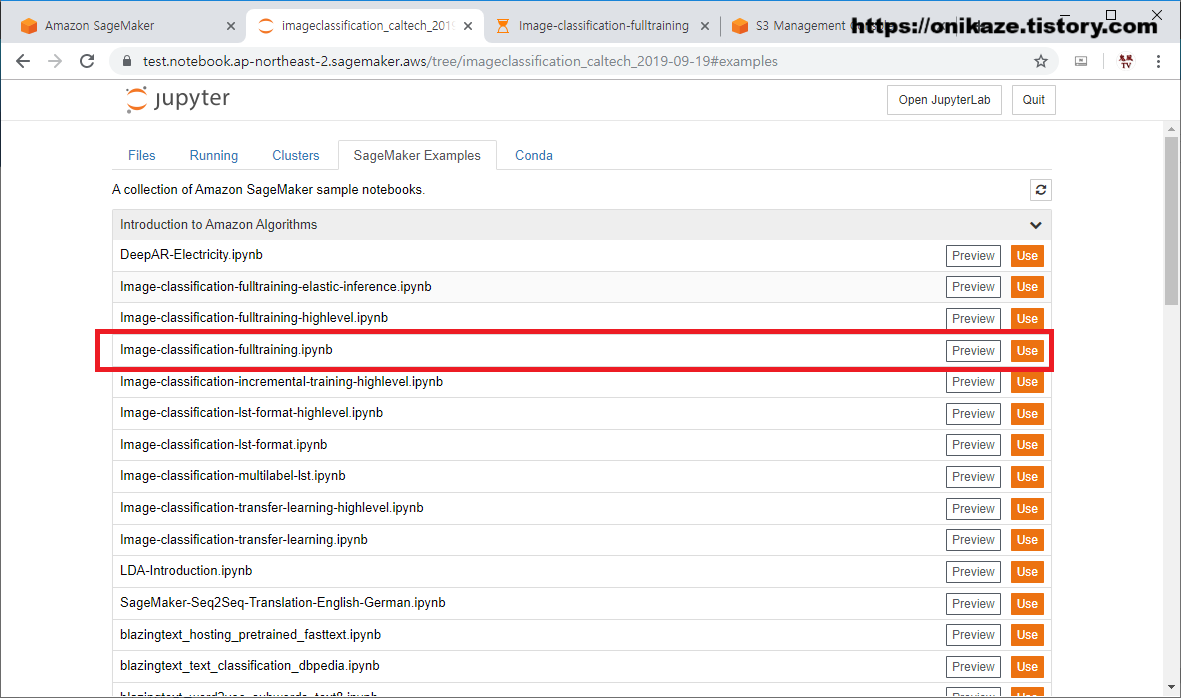
먼저 사용하기 전에 ‘Preview’ 버튼을 누르면 다음과 같이 어떤 알고리즘이고 어떻게 실행되는 지에 대한 자세한 설명이 나와있습니다.
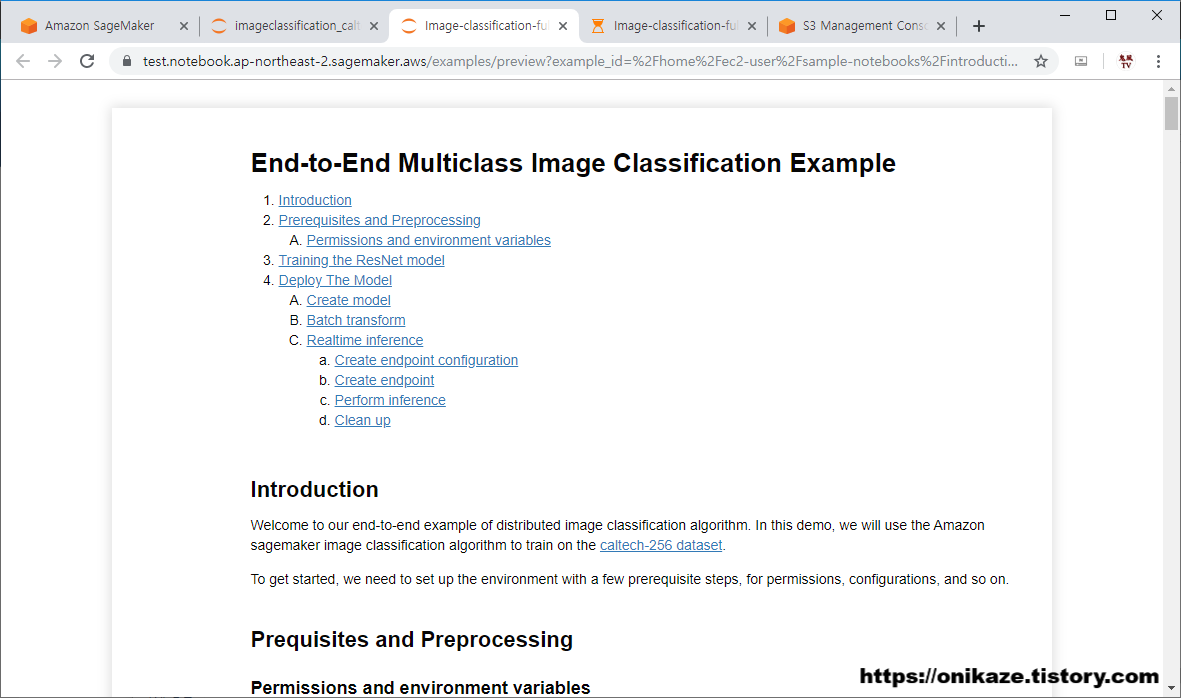
그래서 이 부분을 참고하시면 예제 프로그램을 실행하기 전에 도움이 될 것입니다. 일단 이 부분에 대한 설명은 별도로 하지 않고, 예제 프로그램을 실행하면서 같이 설명하는 순서로 하겠습니다.
다시 알고리즘 목록 화면으로 간 후, ‘Use’를 누르겠습니다. 사용을 하려고 하면 다음과 같이 Image Classification Fulltraining 알고리즘 뿐만 아니라 Image Classification과 관련된 모든 Python 파일을 복사하는 과정을 거치게 되는데요. ‘Create Copy’를 눌러서 진행하시면 됩니다.
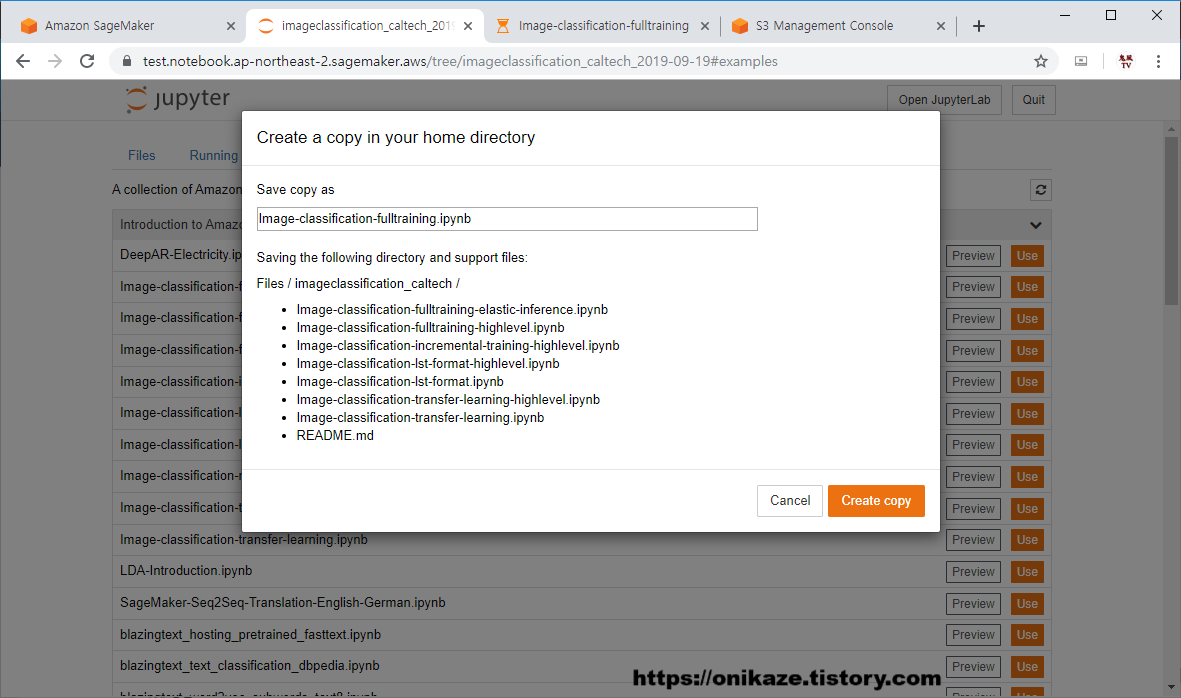
복사가 완료되면, 예제 코드가 Jupyter Notebook에서 보여지게 되며, 이제 단계 별로 하나씩 실행하면 되겠죠?
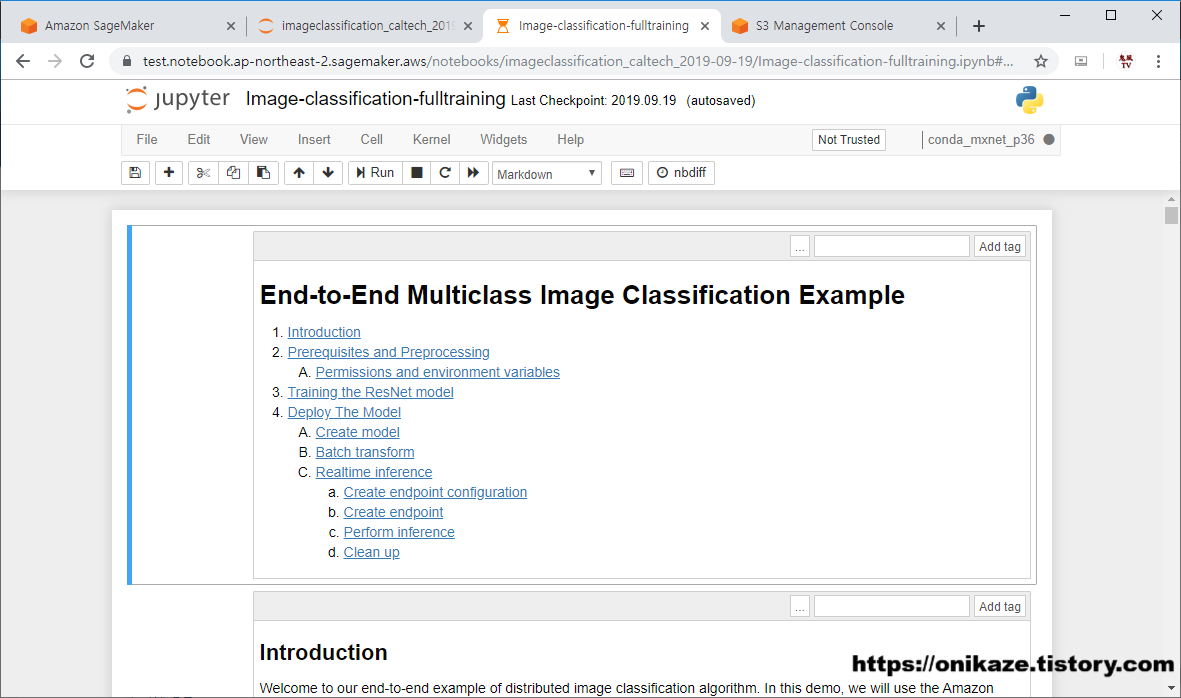
그러면 코드를 실행하기 앞서서 Sagemaker의 노트북 인스턴스의 구조에 대해서 잠깐 설명을 하겠습니다.
노트북 인스턴스라고 함은 Jupyter Notebook, JupyterLab 사용을 위한 하나의 가상 인스턴스입니다. 그래서 앞선 글에서 노트북 인스턴스를 생성할 때에도 인스턴스의 용량 및 규격(ml.t2.medium)을 설정하도록 되어 있으며, 머신러닝 알고리즘을 가동할 때에도 이러한 인스턴스의 CPU, 메모리에 맞춰서 구동합니다. 앞서 예제 코드를 복사한다고 되어 있는데, 이러한 코드는 노트북 인스턴스의 가상 공간에 복사하는 것을 뜻하는 것으로 이해하시면 됩니다.
예제 코드를 하나씩 실행하게 되면 머신러닝에 필요한 학습(Training) 데이터와 검증(Validation) 데이터를 가져오는 부분이 있는데, 이러한 데이터는 노트북 인스턴스에 저장하기에는 대용량의 데이터이기 때문에, 이러한 데이터는 S3에서 관리하는 것을 권장합니다. 그렇기 때문에 노트북 인스턴스를 생성할 때에도 IAM 정책에서 어떤 유형의 S3를 사용할 것인지를 설정하는 부분이 있는 것이니 참고하시면 됩니다.
잠깐 설명이 길었네요. 그러면 코드를 하나씩 실행하도록 하겠습니다.
코드는 꽤 긴 코드로 구성되어 있습니다. 그렇기 때문에 코드에 대해서 일일이 설명하거나 그러지는 않겠습니다. 다만, 전체적인 흐름에 대한 설명과 SageMaker 서비스에서 제공하는 메소드 등에 대한 부분만 간단하게 언급할 예정입니다. 실제 예제 코드에서는 각 코드나 변수에 대한 설명도 일부는 자세히 나와 있으니 관련 문서를 참고하시면 좋을 것입니다.
1. Prerequisites and Preprocessing (전제조건 및 전처리)
쉽게 말해서 실제 머신러닝 수행을 위한 환경변수 설정 및 전처리 작업을 수행하는 부분으로 보시면 됩니다.
머신러닝에 필요한 데이터가 학습(Training), 검증(Validation), 테스트(Test) 데이터로 구성되어 있는 것은 아마 알고 계실 것이라 생각합니다. 이 부분에서는 기본적인 환경을 설정하고, 학습 및 검증 데이터를 다운로드하는 부분으로 구성되어 있습니다.
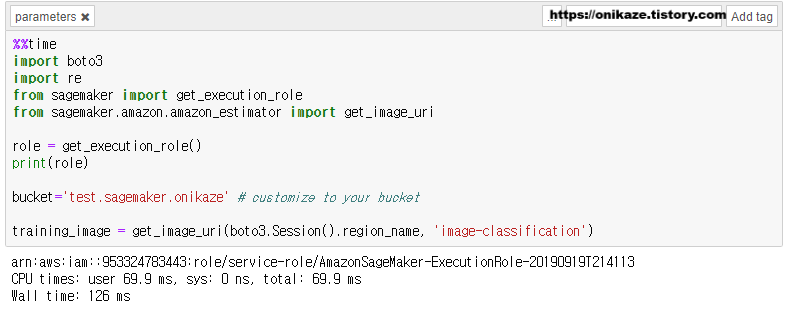
첫 번째 코드입니다. 여기의 bucket명은 이 부분은 직접 입력해야 하며, S3 버킷명을 입력합니다. 노트북 인스턴스 생성 시에 일반적으로 이름에 ‘Sagemaker’가 들어간 버킷에 대해서 접근을 허용하기로 되어 있으므로, 위에 명시된 이름의 S3 버킷이 사전에 생성되어 있어야 합니다.
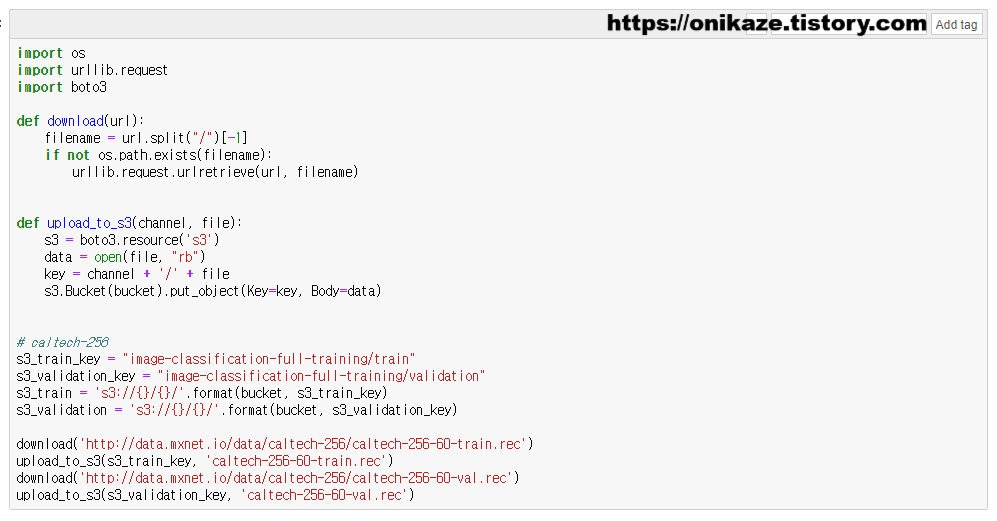
download, upload_to_s3는 사용자 함수입니다. 함수명 그대로 download는 웹에 있는 데이터 파일을 노트북 인스턴스에 다운로드하고, upload_to_s3는 노트북 인스턴스에서 다운로드받은 데이터를 s3에 업로드합니다. 그리고 s3_train / s3_validation 부분은 학습, 검증 데이터에 대한 s3 경로 지정을 위한 변수입니다.
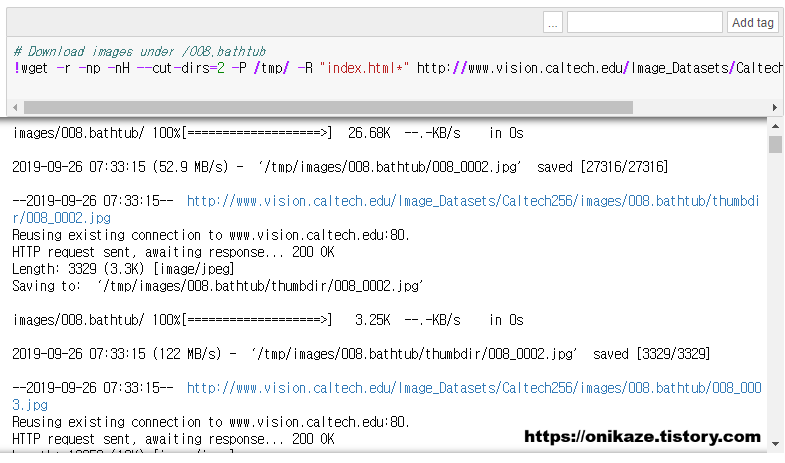
맨 아래 보시면 http://data.mxnet.io/data/caltech-256/caltech-256-60-train.rec 파일과 caltech-256-60-val.rec 파일을 다운로드 후 S3 버킷에 업로드하는 구문이 있습니다. 이 구문을 실행하면 실제 해당 파일이 S3 버킷에 저장됩니다. 용량이 다소 크기 때문에 약간의 시간이 걸리며, 업로드 완료 후 S3 버킷에 어떻게 저장되었는지를 한번 확인해볼게요.
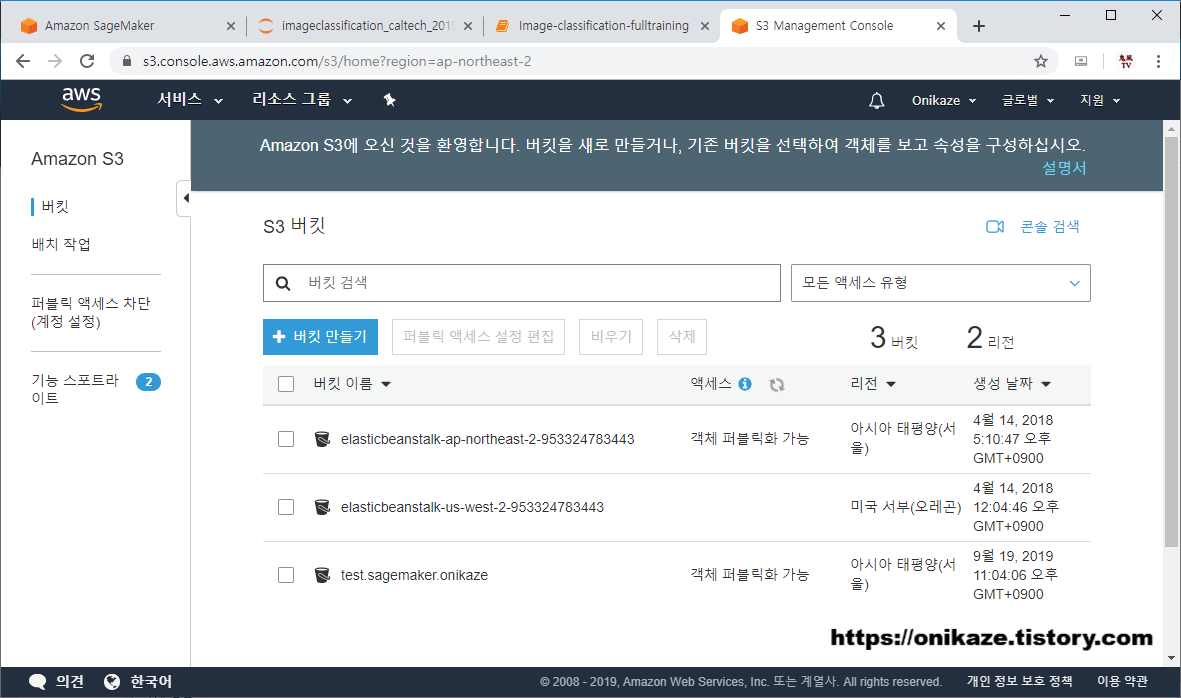
세 번째 ‘test.sagemaker.onikaze’는 이번 테스트를 위해서 사전에 생성했던 버킷입니다. 물론 처음 생성했을 때에는 빈 버킷이였습니다.
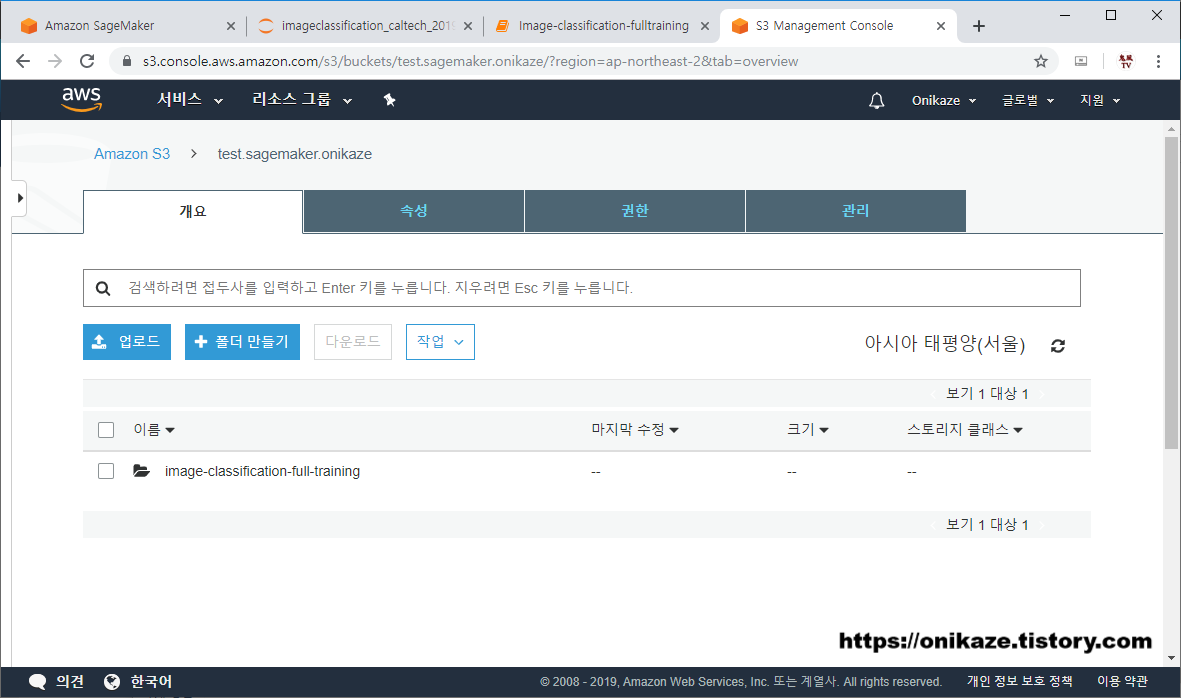
하지만 들어가 보니 ‘image-classification-full-training’이라는 디렉토리가 생성된 것을 확인할 수 있습니다. 위의 예제에서 코드를 실행해서 디렉토리 또한 생성되었습니다.
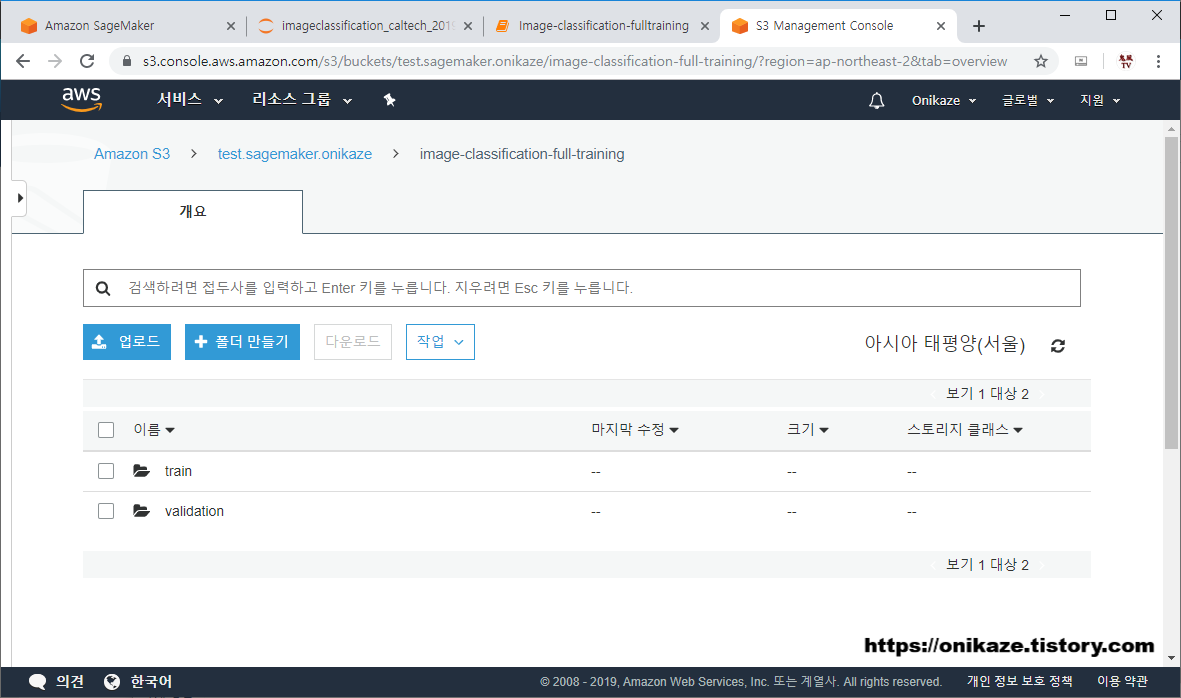
다음은 안에 생성된 디렉토리입니다. ‘train’과 ‘validation’ 디렉토리가 생성된 것을 확인할 수 있을 것입니다.
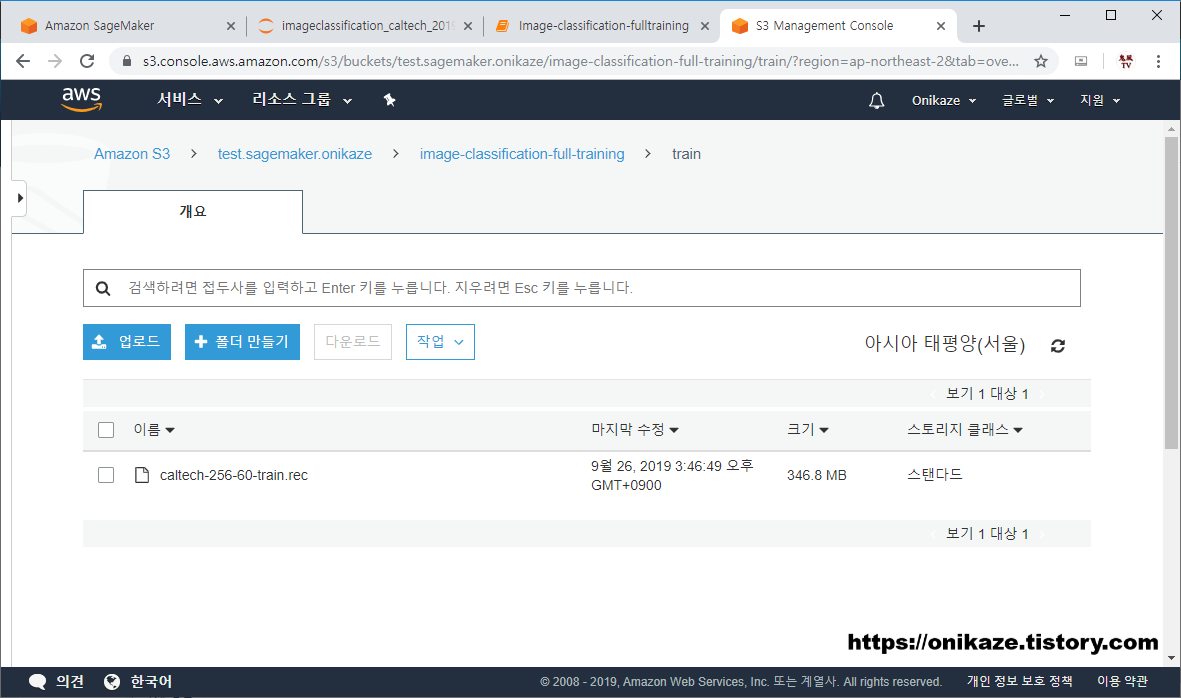
train 디렉토리를 들어가면 위와 같이 caltech-256-60-train.rec 파일이 정상적으로 있는 것을 확인할 수 있을 것입니다. validation 디렉토리 역시 마찬가지로 caltech-256-60-validation.rec 파일이 생성되어 있을 것입니다. validation에 대한 첨부 이미지는 생략합니다.
2. Training the ResNet Model (ResNet 모델 학습)
여기서 ResNet이라고 하는 것은 Deep Learning에서 사용되는 Residual neural Network의 줄임말로, 딥러닝에서 사용되는 모델이라고 합니다. 솔직히 이 부분이 구체적으로 무엇이다라는 것을 설명하려면 한도 끝도 없기 때문에 그냥 이런 것 정도 있다라는 것만 이해하고 넘어가시면 될 것 같고요.
Caltech-256 데이터는 256개의 객체의 30,608개의 Image가 있는 데이터로, 이를 대상으로 분류하는 작업을 진행할 예정이라 합니다. 256개 객체가 뭔지는 아래 사이트에서 확인할 수 있으니 참고 정도만 하시면 되겠고요.
http://vision.caltech.edu/Image_Datasets/Caltech256/images/
다음은 학습을 위한 파라미터 변수를 설정하는 부분입니다. 변수에 대한 설명은 생략합니다.

실제 훈련을 수행하기 위해서는 훈련에 필요한 파라미터 변수가 필요합니다. 이를 training_params 변수로 하여 다음과 같이 구성합니다. 여기서 job_name_prefix 변수는 기본으로 설정되어 있지 않으므로 그냥 실행하면 에러가 발생하므로, 임의의 이름으로 변수 선언부를 추가해주시면 됩니다.

이제 실제 모델 학습을 진행하는 부분입니다. 앞서 선언한 파라미터를 바탕으로 모델 학습을 진행하며, sagemaker.describe_training_job 메소드를 사용합니다. 시간은 꽤 오래 걸리니 기다리시면 될 것 같습니다.
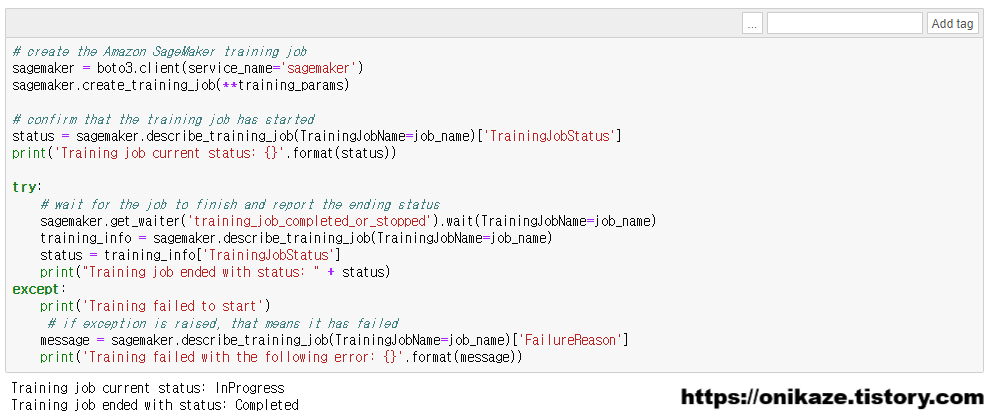
모델 학습이 완료된 후 한번 더 확인하는 부분입니다. 사실 이 코드는 바로 위 코드와 중복되므로 실행하지 않아도 문제없습니다.

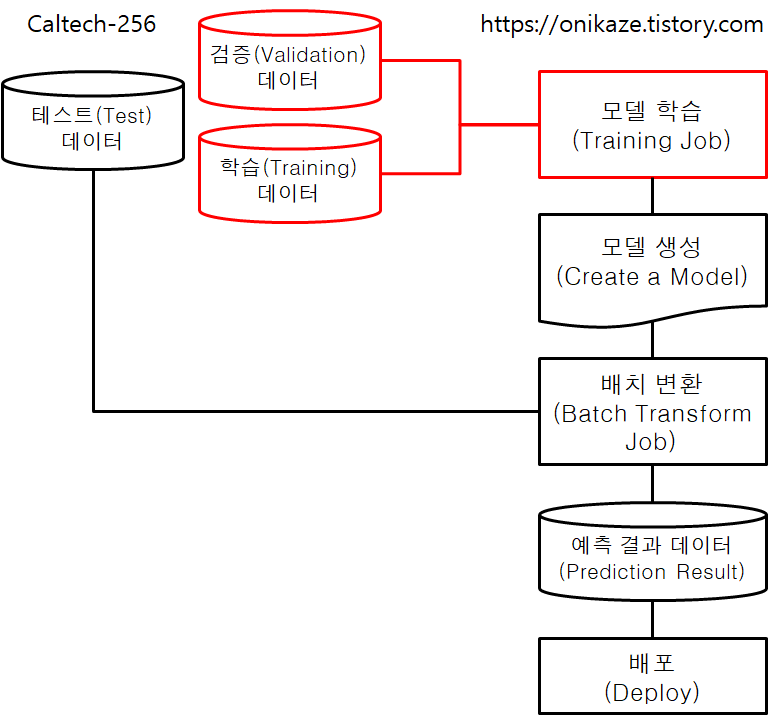
모델 학습은 여기까지 완료되었으며, 전체 프로세스 중 아래 표시돤 단계를 진행한 것으로 보시면 됩니다.
3. Deploy the model(모델 배포)
모델 학습(Training job)이 완료되었으면, 이제 다음 단계를 수행합니다.
1) 실제 모델을 생성하고
2) 배치 변환을 통해서 예측 결과를 생성한 후
3) 생성된 데이터를 배포합니다.
그렇다면 각 단계별로 진행하겠습니다.
1) 모델 생성(Create Model)
모델 생성은 전체 프로세스 중 아래 표시된 단계에 속하며, 모델 학습을 바탕으로 해서 생성이 이루어집니다.
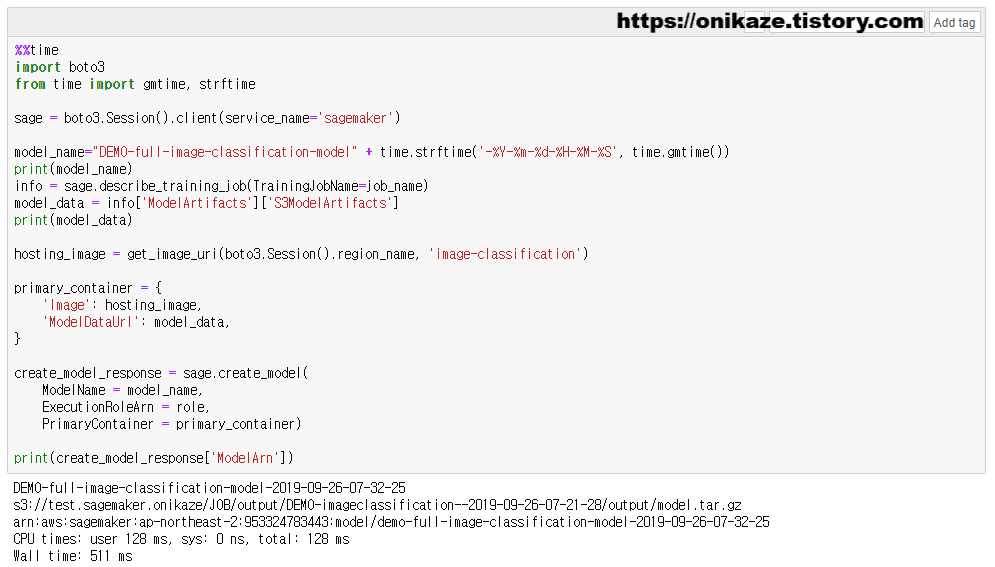
모델 생성은 sage.create_model 메소드를 사용하며, 모델은 S3 버킷에서 생성되므로 S3 버킷 경로도 같이 지정합니다.
모델 생성이 완료되었으면, S3 버킷으로 가봅니다.
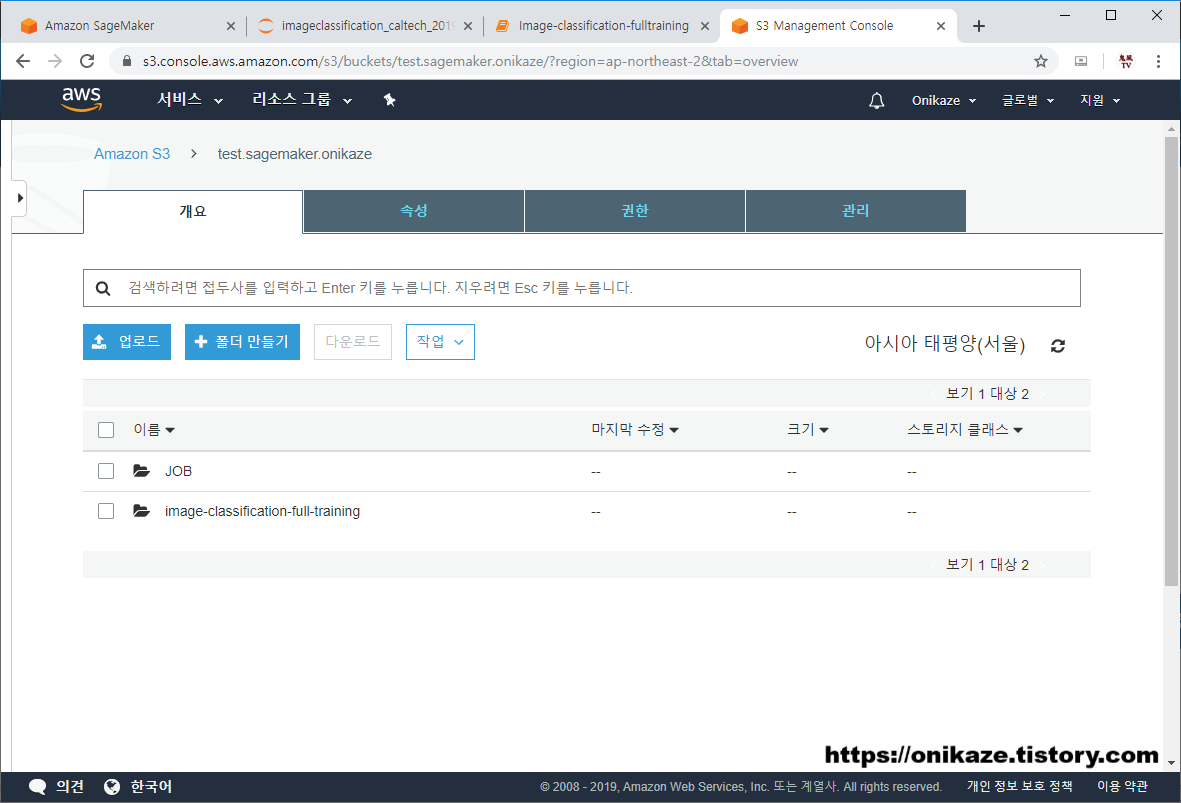
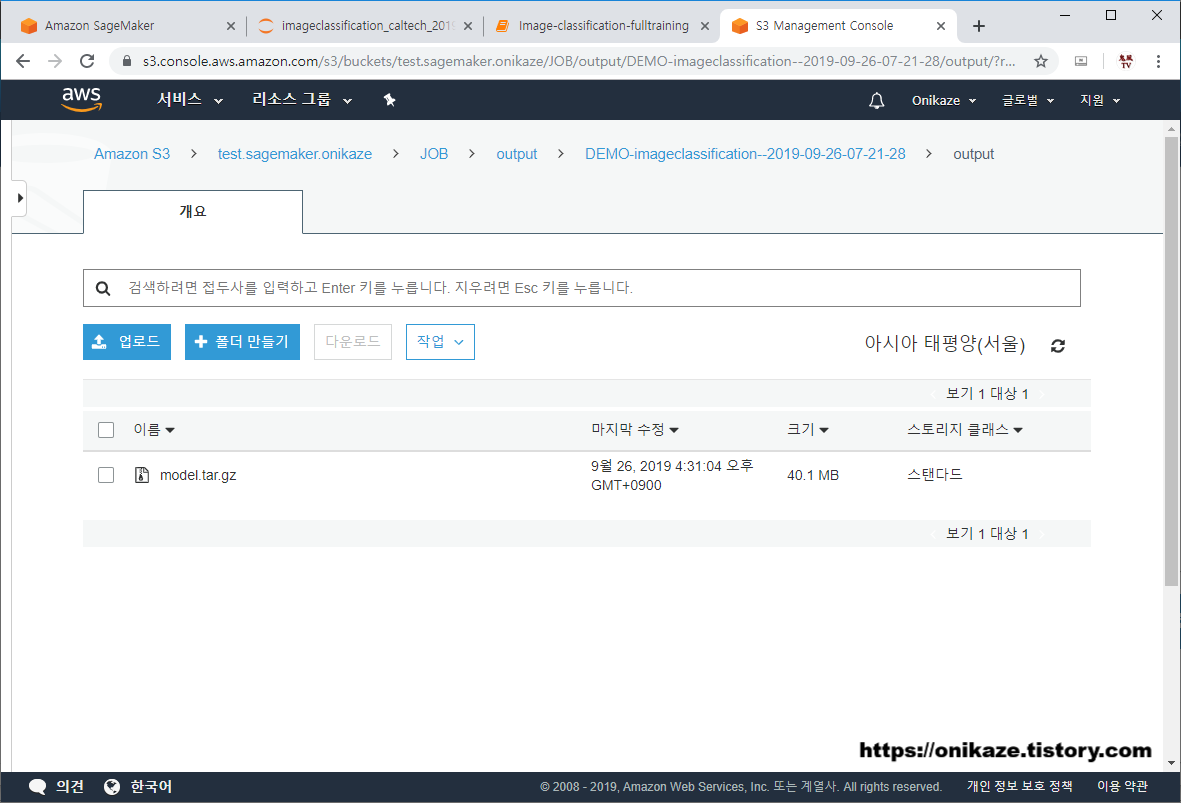
위와 같이 ‘JOB’이라는 디렉토리가 생성된 것을 확인할 수 있습니다. ‘JOB’ 디렉토리는 위의 모델 학습에서 파라미터 지정 시 job_name_prefix 변수의 값으로, 실제 경로는 JOB/output/DEMO-imageclassification-2019-09-26-07-21-28/output 에 생성됩니다.
그래서 생성된 모델을 보면 아래와 같습니다. tar.gz 압축파일로 생성된 것이 확인되었네요.
2) 배치 변환(Batch Transform)
배치 변환을 위해서는 먼저 테스트 데이터를 다운로드받은 후, 테스트 데이터를 모델에 대입해서 예측 결과(Prediction Result)를 생성하는 순서로 이루어집니다. 전체 프로세스의 아래 표시된 부분으로 보시면 됩니다.
먼저 테스트 데이터를 다운로드받습니다.
다운로드가 완료되면 S3 버킷으로 다시 업로드합니다.

S3 버킷을 확인해볼까요.
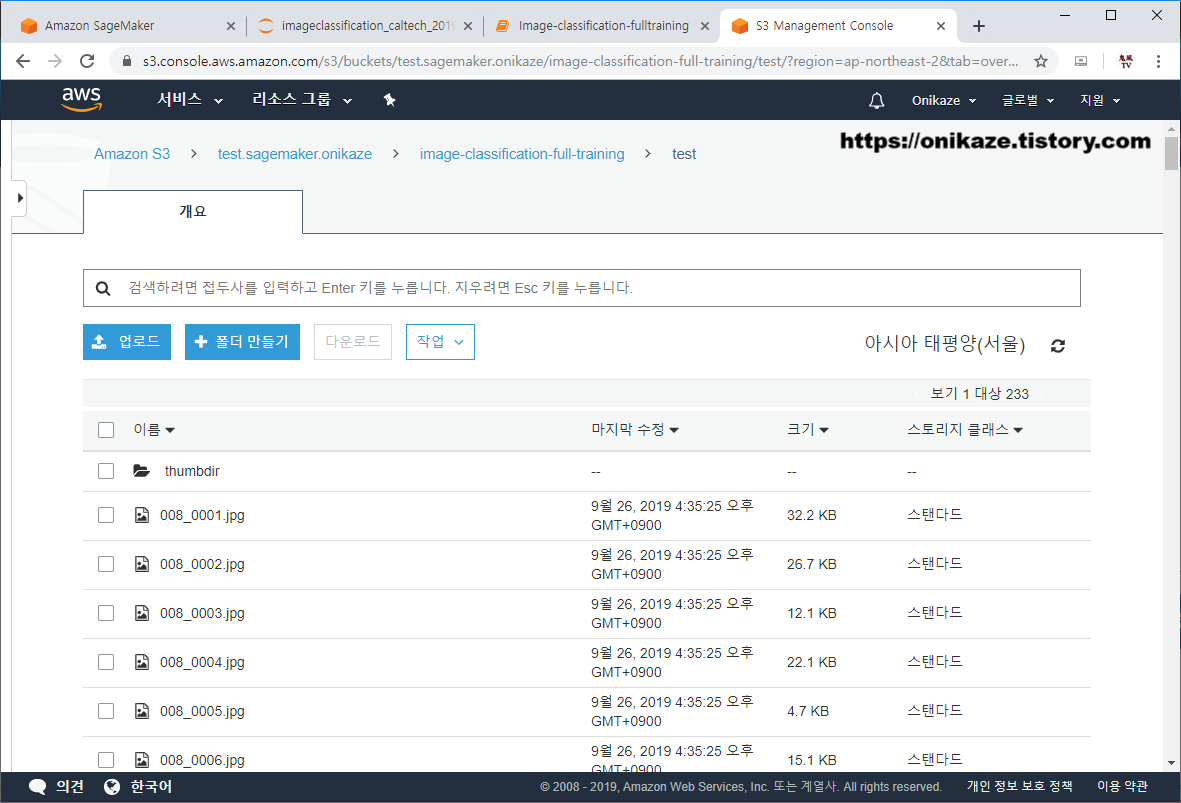
image-classification-full-training 디렉토리에 /test가 새로 생긴 것을 알 수 있습니다.
/test 디렉토리에는 테스트 데이터를 위한 232개의 Image 파일이 있는 것을 알 수 있습니다.
다음은 배치 변환을 위한 파라미터를 생성하는 부분입니다. 앞서 모델 학습에 필요한 파라미터를 생성하는 것과 같은 맥락으로 보시면 됩니다.
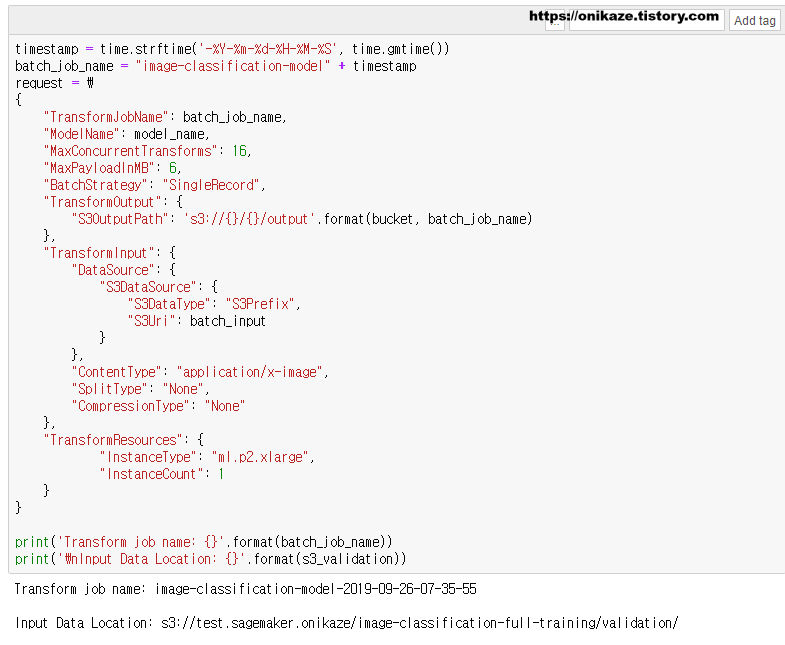
파라미터 입력이 완료되었으면, 이제 실제 배치 변환 작업을 수행합니다. 배치 변환은 sagemaker.describe_transform_job 메소드를 사용하며, 시간이 가장 오래 걸리는 작업입니다.
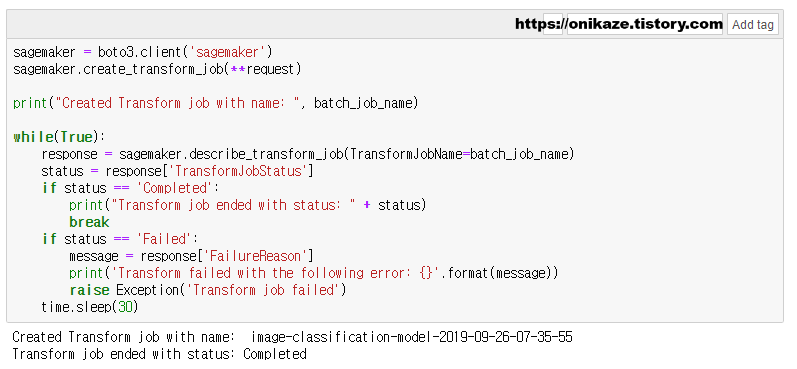
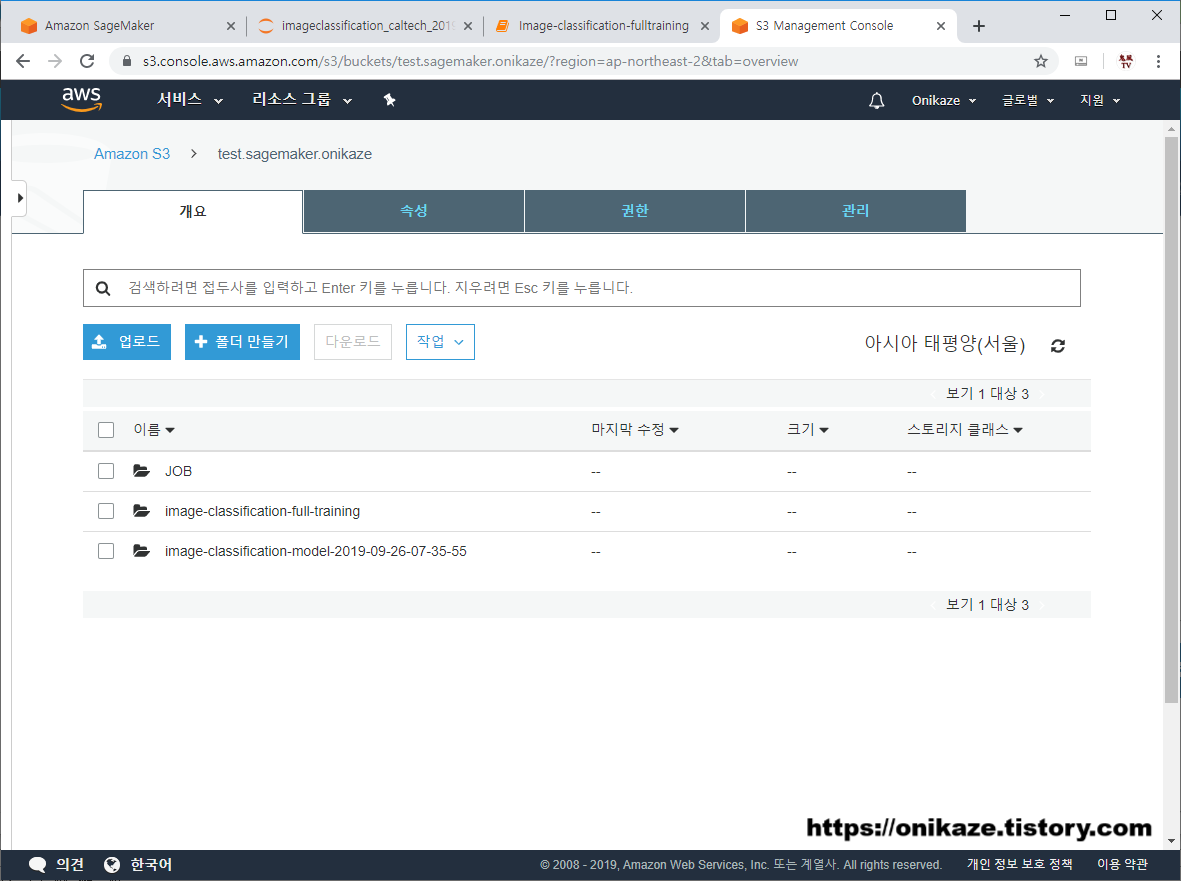
긴 시간 동안 배치 변환이 완료되었으면, 예측 결과 데이터가 생성되며, 예측 결과 데이터는 S3 버킷에서 생성됩니다. S3 버킷을 확인하면 ‘image-classification-model-2019-09-26-07-35-55’ 디렉토리가 새로 생성된 것을 확인할 수 있습니다.
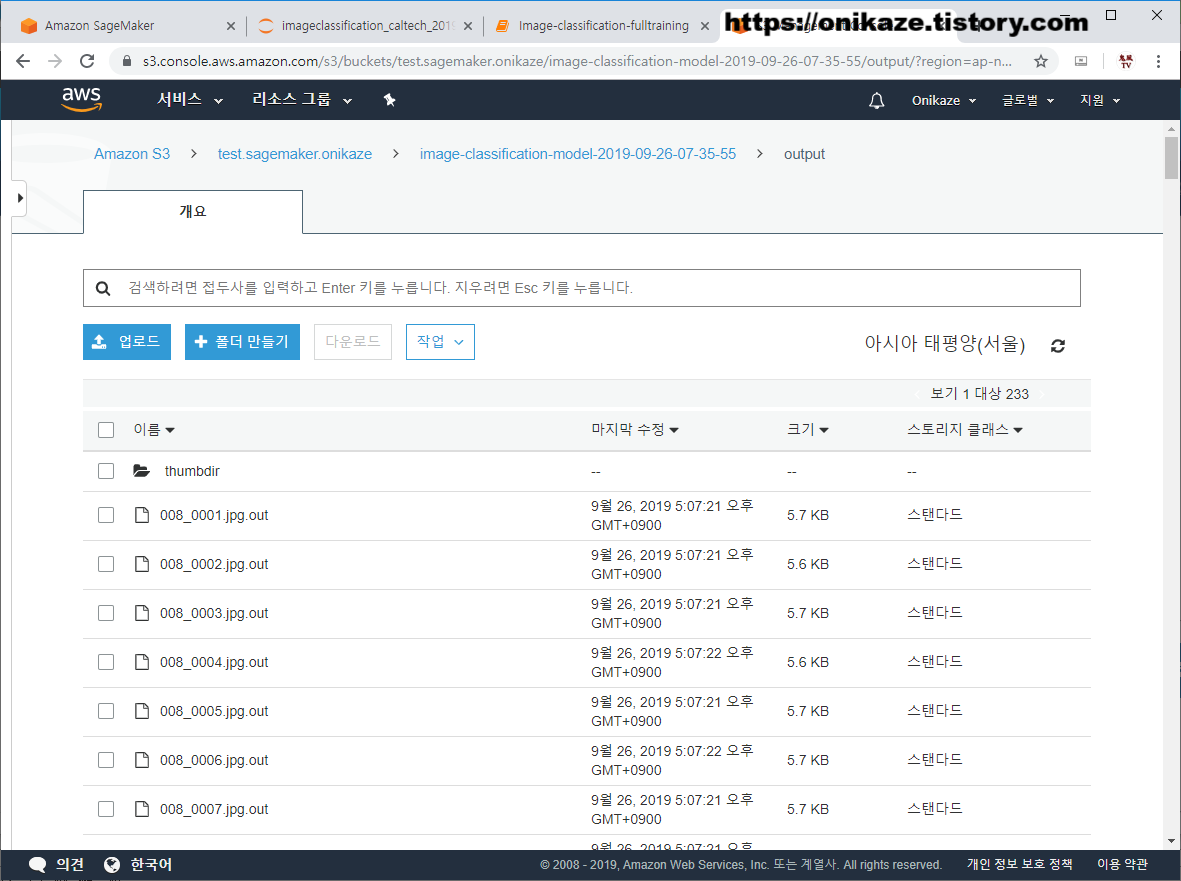
디렉토리 내부로 들어가면 배치 변환을 통해서 나온 예측 결과 파일이 생성된 것을 확인할 수 있습니다. 232개의 테스트 데이터 각각에 대해서 예측 결과도 각각 생성된 것을 확인할 수 있습니다.
예측 결과 데이터 생성까지 완료되었으면, 테스트 데이터 - 예측 결과 데이터를 비교하여 검사하는 구문입니다.
샘플 데이터는 2개입니다. 입력 데이터는 008_0001.jpg와 008_0002.jpg 파일이고, 출력 데이터는 008_0001.jpg.out과 008_0002.jpg.out으로 예측 결과 데이터입니다. 001.jpg, 002.jpg에 대한 예측 결과가 001.jpg.out, 002.jpg.out으로 나왔으니, 앞의 10개의 데이터에 대해서는 2개의 샘플 데이터를 바탕으로 예측했을 때 어떤 결과가 나오는지를 나타내는 부분입니다.
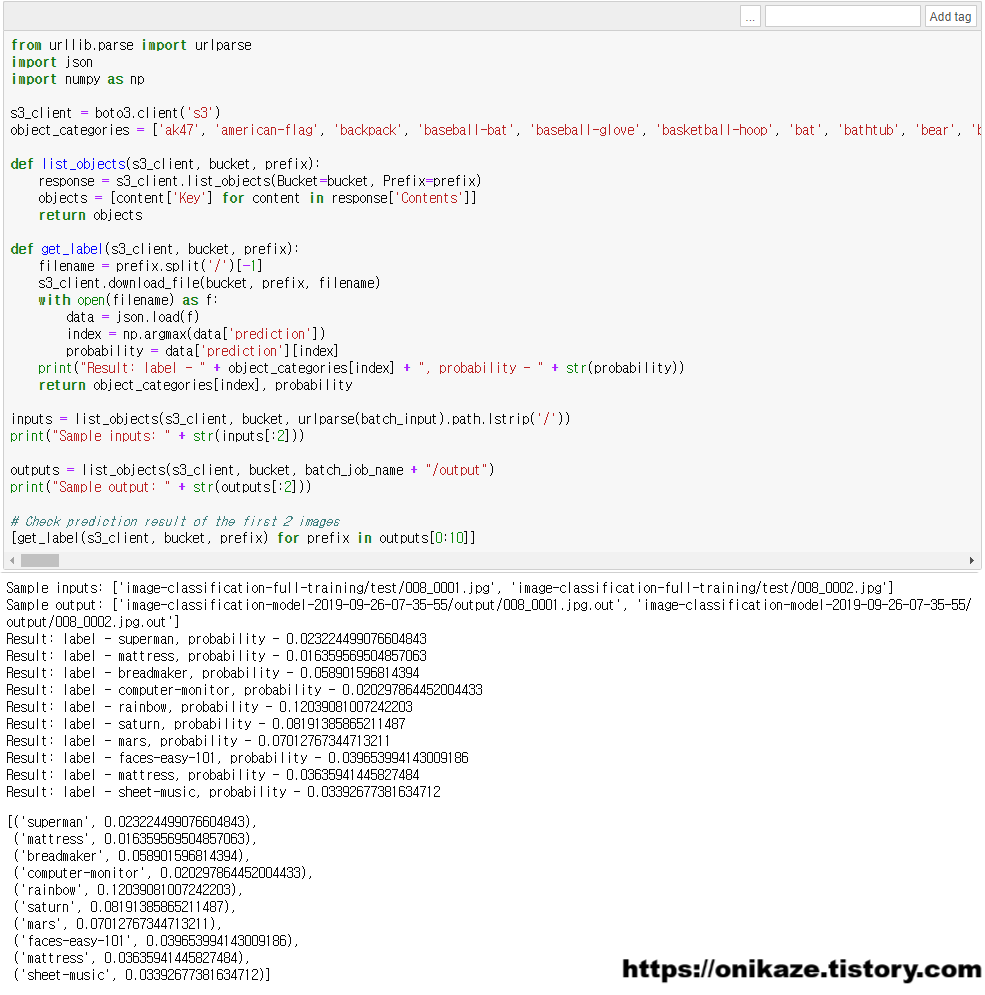
바로 위 결과를 보면 10개의 데이터에 대한 예측 결과가 나타나는 부분으로, 각각의 확률을 표시하는 것을 알 수 있습니다. 이 글은 결과를 분석하는 글이 아닌 예제를 설명하는 글이므로 분석은 생략하겠습니다.
3) 실시간 추론을 위한 모델 배포(Host the model for realtime inference)
이제 실제 모델을 배포하는 부분입니다. 전체 프로세스의 가장 마지막에 해당하는 부분으로 보시면 됩니다.
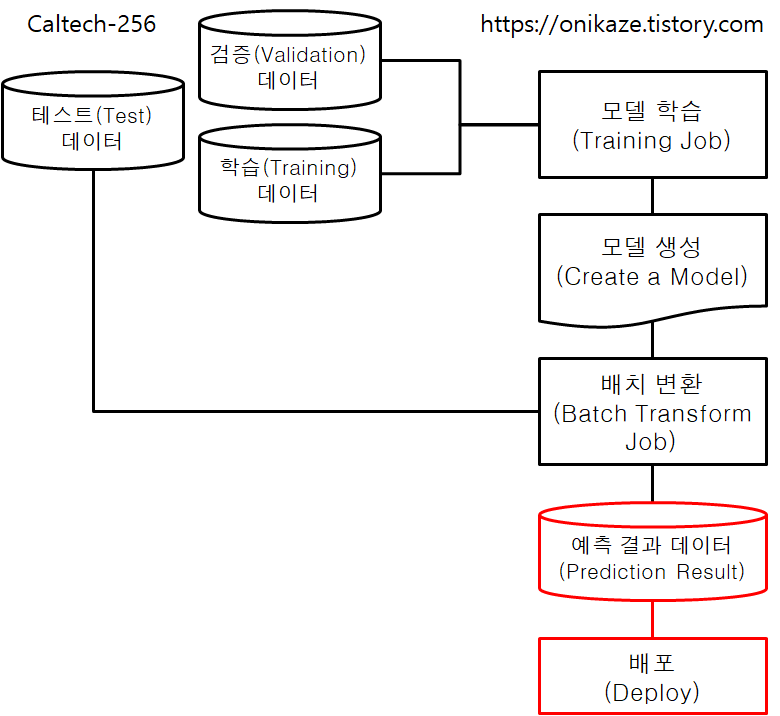
앞서 다루었던 부분은 머신러닝을 위한 학습을 하고, 모델을 생성한 후, 테스트 데이터를 바탕으로 한 예측 결과 생성까지 진행했었습니다. 이제는 이러한 모델 및 데이터를 실제 배포하는 작업을 진행할 예정입니다. 데이터 및 모델 배포가 이루어지면 머신러닝 수행을 위해서 외부 애플리케이션 등과 연동할 수 있습니다.
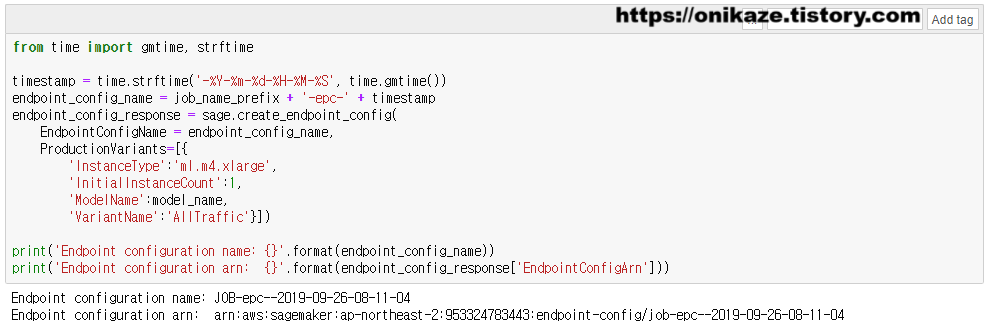
먼저 엔드포인트(Endpoint) 환경설정(Configuration) 부분입니다. 어떤 유형으로 엔드포인트를 생성할 것인지를 설정하는 부분이겠죠. 엔드포인트 환경설정은 sage.create_endpoint_config 메소드를 실행하여 생성합니다.
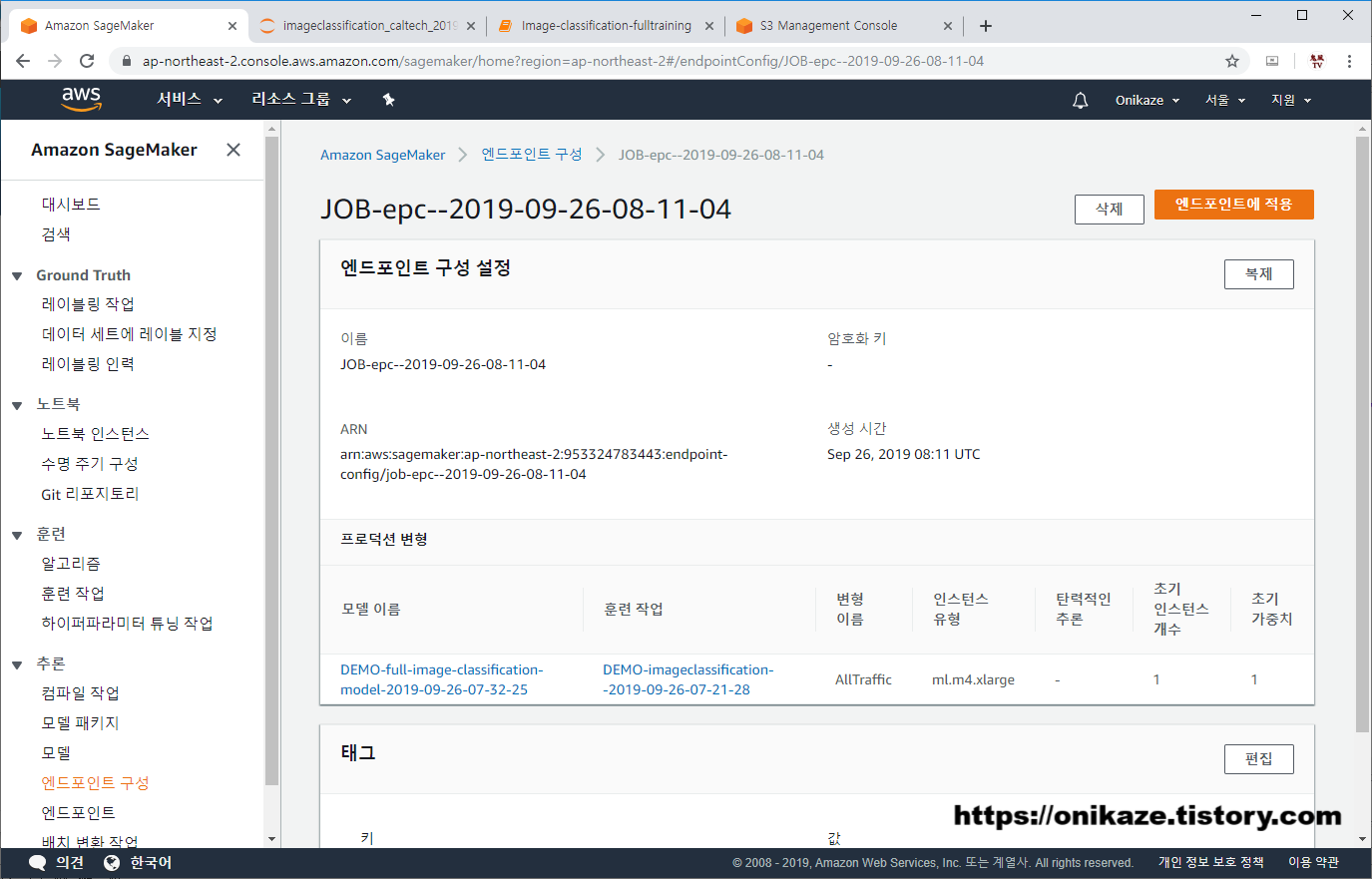
엔드포인트 구성이 완료되면 Sagemaker의 추론 - 엔드포인트 구성으로 가면 새로 생성된 것을 확인할 수 있을 것입니다. 아래 사진에서 ‘DEMO-‘로 시작한 것은 제가 예전에 만들었던 구성이고, 여기 글에서 만든 구성은 ‘JOB-‘으로 시작하는 구성이니 참고하시면 되겠습니다.
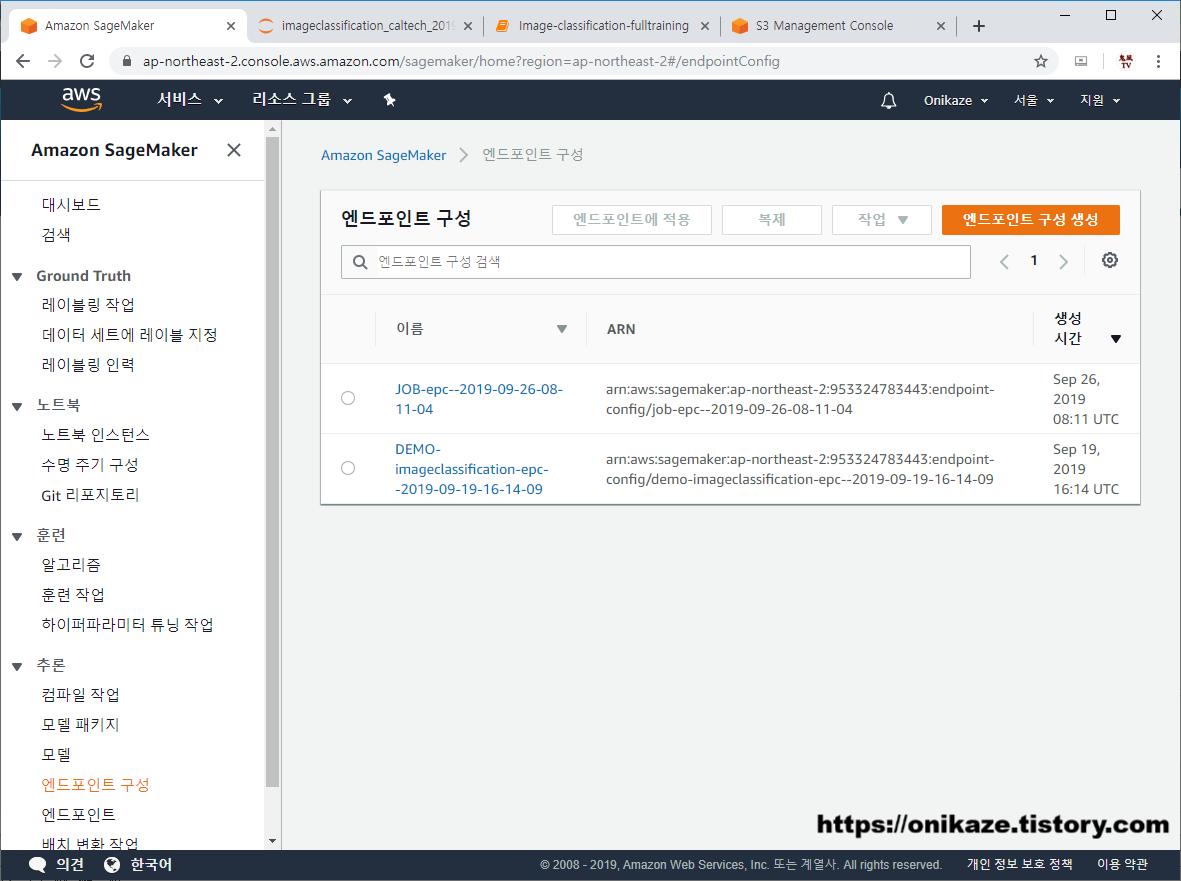
‘JOB-epc–2019-09-26-08-11-04’ 엔드포인트 구성으로 들어가면 상세 내용을 확인할 수 있습니다.
다음은 엔드포인트를 실제 생성하는 부분입니다. sagemaker.create_endpoint 메소드를 사용하며, 환경설정 내용을 바탕으로 생성을 진행합니다.
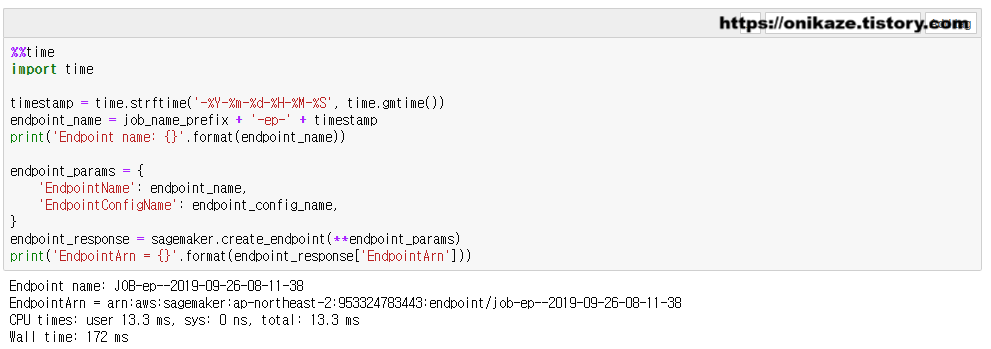
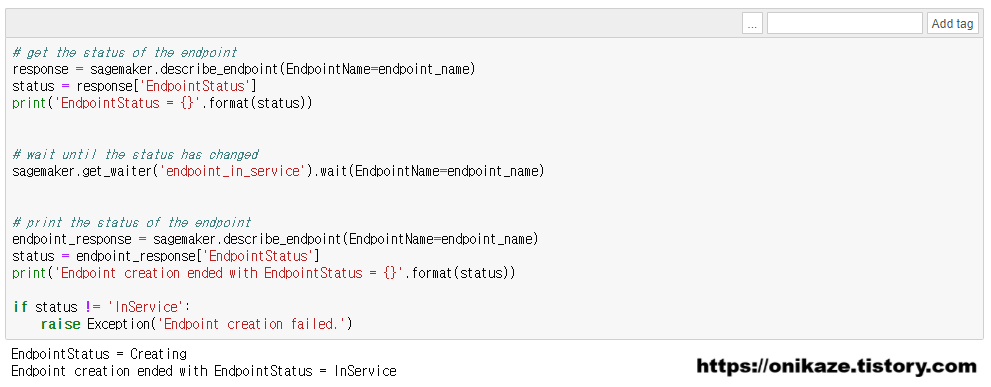
엔드포인트 생성을 진행하였으면, 정상적으로 생성되었는지 상태를 확인해봐야겠죠. 아래 결과와 같이 Creating / InService라고 정상적으로 나타납니다.
엔드포인트가 생성되면 SageMaker에서도 엔드포인트가 아래와 같이 생성됩니다.
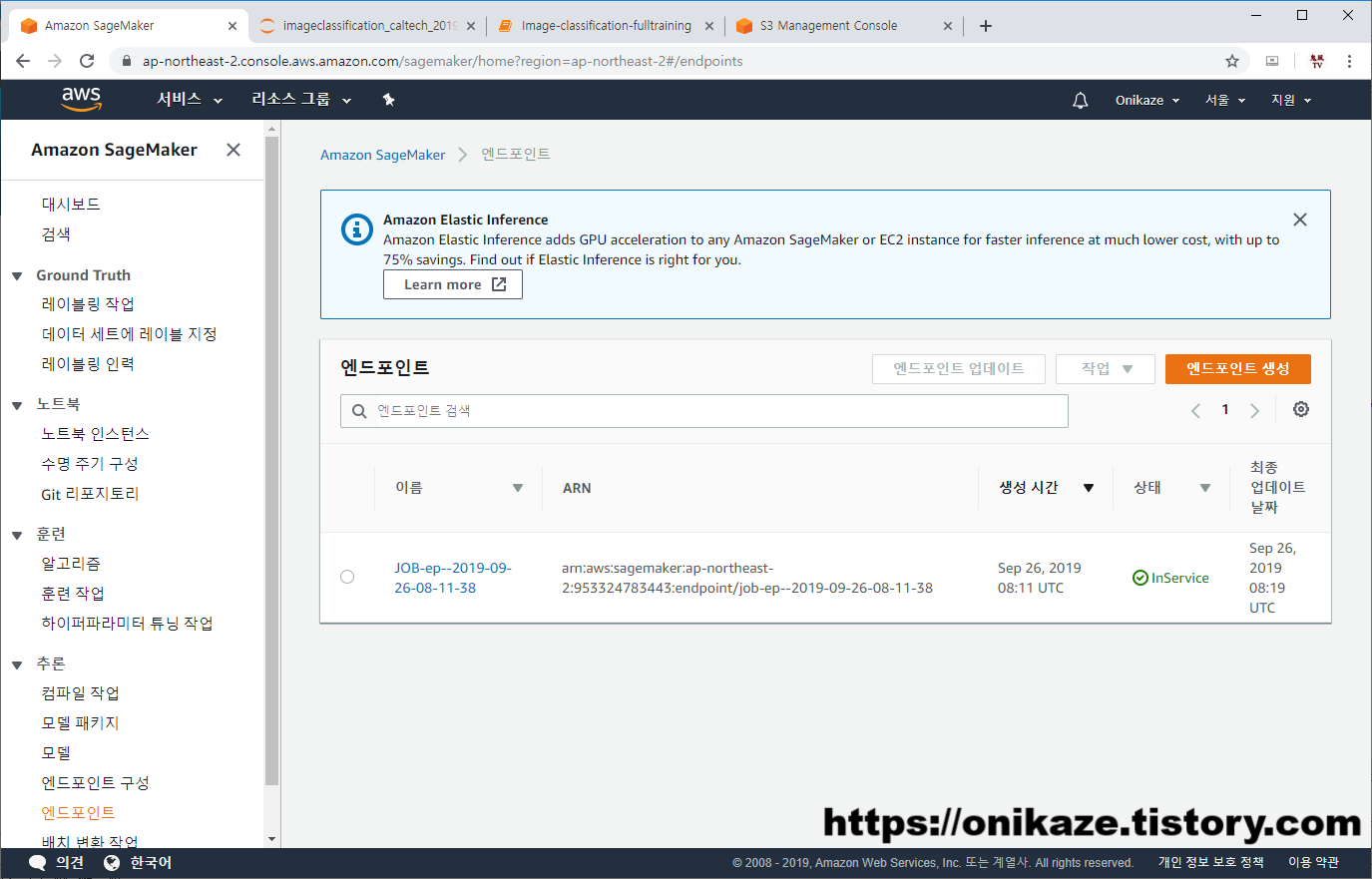
엔드포인트를 들어가면 세부 내용과 모니터링 지표 등을 볼 수 있습니다.
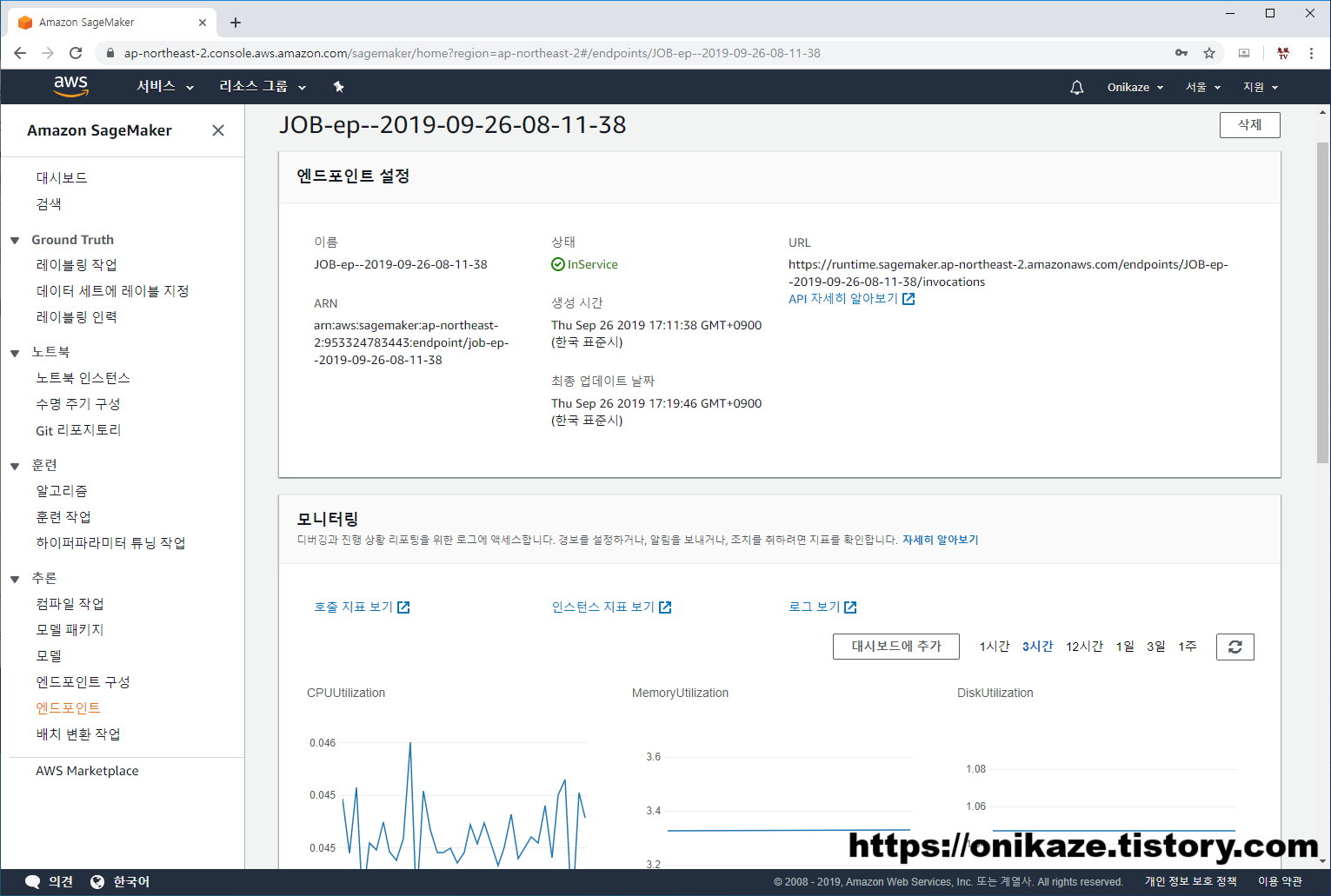
이제 다음은 엔드포인트로 배포된 모델 테스트를 위해서, 임의의 이미지 한개를 다운로드받도록 하겠습니다.

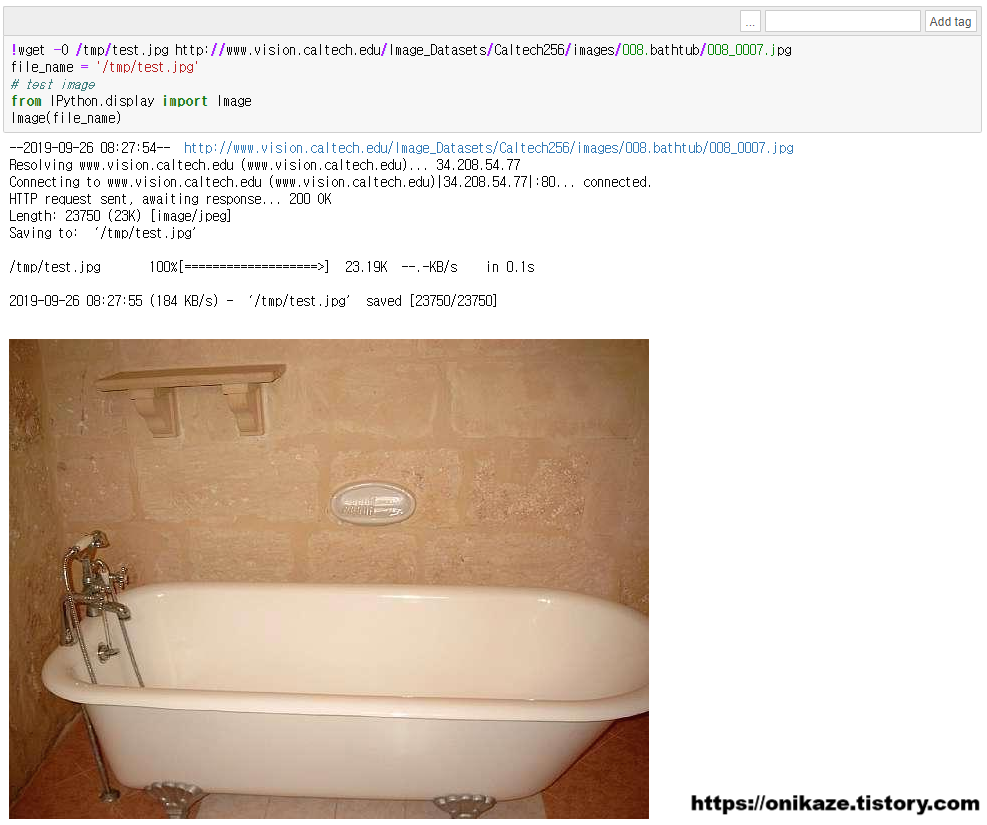
다운로드 받은 이미지는 위와 같은 이미지네요.
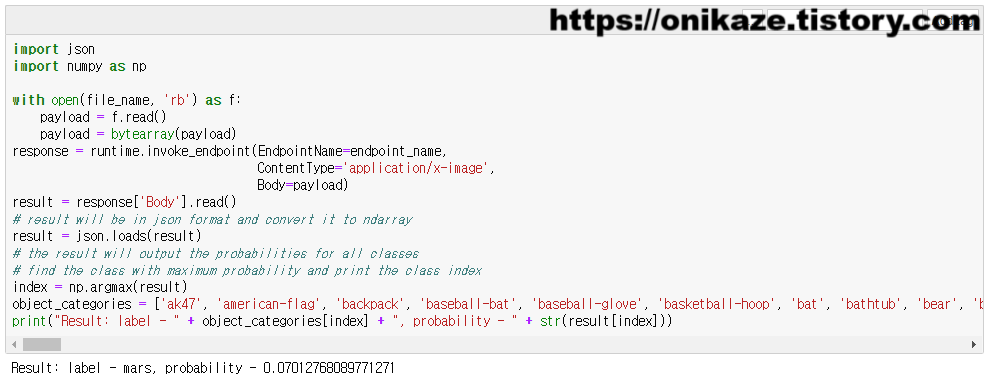
위 이미지를 테스트 데이터로 한 후 runtime.invoke_endpoint 메소드를 실행하여 모델에 대한 결과를 받아오도록 하겠습니다. 결과는 아래와 같이 mars 라벨에 0.0701276… 의 확률로 결과가 나타났네요. 물론 이 결과가 유의미한지까지는 여기서 밝히지는 않겠습니다만, 배포 모델에 대한 테스트가 이루어진 것은 확인할 수 있겠죠.
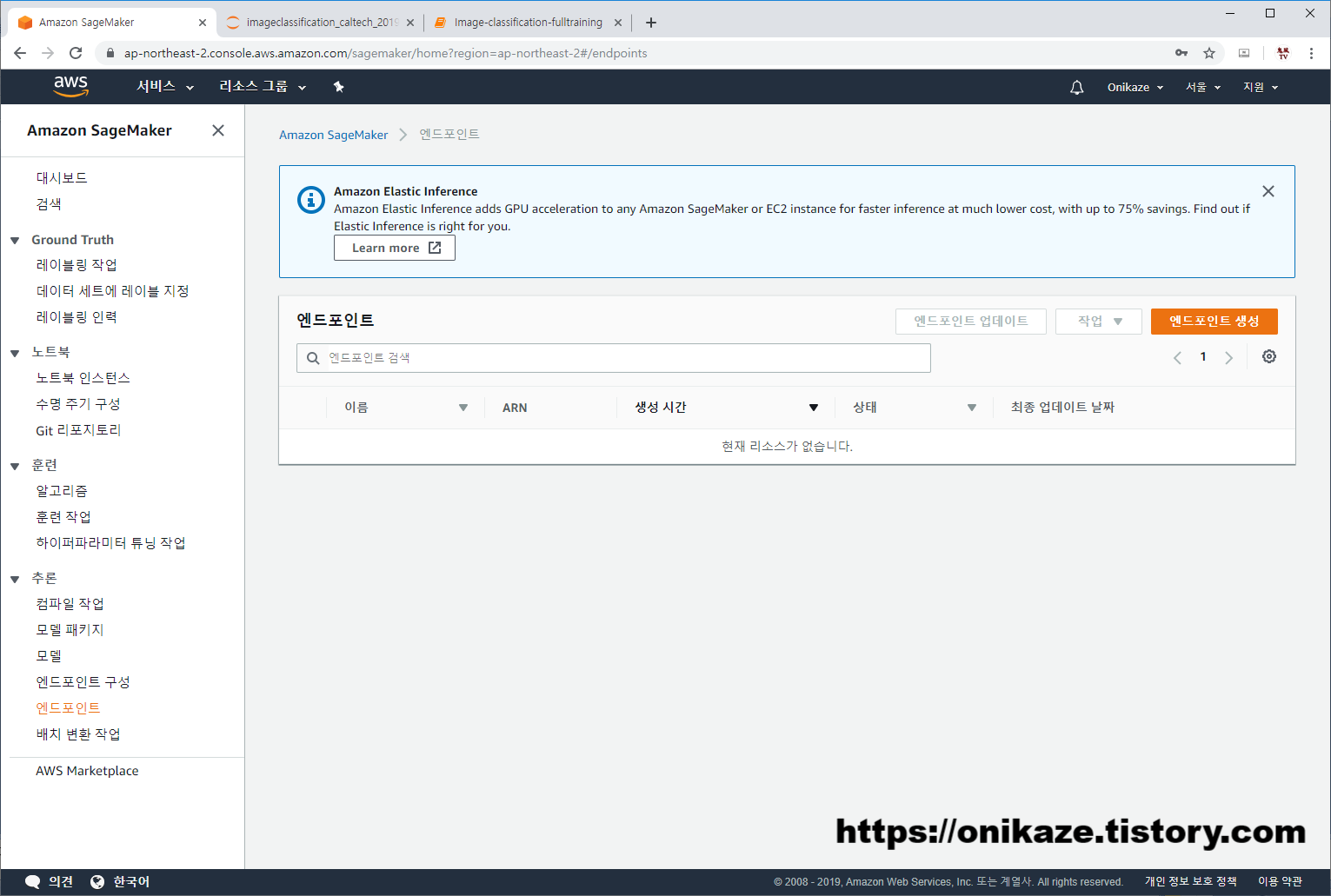
엔드포인트를 더이상 사용할 일이 없다면, 이제 삭제를 진행하겠습니다.

삭제는 간단합니다. 아래와 같이 사라진 것을 확인할 수 있습니다.
Amazon Sagemaker의 머신러닝 알고리즘 중 하나인 Image Classification Fulltraining 예제는 이것으로 마치겠습니다. 저도 머신러닝은 오랫만에 다시 보려니 많이 어렵기도 하고 개념도 안잡히긴 했는데, 예제 코드를 실행하면서 어떤 프로세스로 흘러가는지를 이해하려고 하니 조금은 알 것 같기도 하고 그러네요.
특히 SageMaker를 사용했을 때 머신러닝이 어떤 절차로 수행되고, 머신러닝을 위헤서 어떤 알고리즘과 API를 제공하는 지에 대해서도 알 수 있었던 것 같습니다.
이상 글 마치겠습니다.
감사합니다.