이미지 텍스트 추출 API 비교 - Tesseract vs Google Vision API
이번에 쓸 글은 이미지에서 텍스트를 추출하는 기술인 OCR(Optical Character Recognition) API로 사용되는 Tesseract-OCR과 Google Vision API를 간단히 비교하는 글을 쓰겠습니다.
Tesseract-OCR
먼저 Tesseract-OCR은 OCR API 중 오픈소스(Open Source)로 가장 유명한 API입니다. 그에 비해 Google Vision API는 딥러닝(Deep Learning) 기술을 이용해서 텍스트 추출에 대한 학습을 하여 최적의 텍스트 추출을 위한 기능을 제공하고 있습니다.
Tesseract-OCR은 C, C++ 언어로 제작된 API이기 때문에, 호환되는 다른 프로그래밍 언어에서 작업하더라도 최소한 gcc 등의 C Complier는 반드시 설치되어 있어야 하며, C++, Python, Java 등 다양한 언어를 통해서 사용 가능합니다.
Google Vision API
Google Vision API는 Google Cloud에서 제공하는 서비스 중 하나로, API를 사용할 때마다 일정 요금이 부과되는 서비스입니다. 물론 Google Cloud를 최초에 가입할 경우에는 무료 Credit을 부여하기 때문에 일정 기간 또는 용량 범위 내에서는 무료로 사용이 가능합니다. 저 또한 이러한 무료 Credit을 통해서 Vision API를 사용하고 있고요.
Vision API는 사실 이미지에서 텍스트를 추출하기 위한 전용 기술은 아닙니다. 이미지에 대한 다양한 처리를 수행하며, 그 중에서 텍스트 추출은 그 기능의 일부분으로 보시면 됩니다. 그렇다면 이러한 다양한 처리가 무엇인지 간단하게 살펴보겠습니다.
- 광학 문자 인식(OCR)
- 텍스트 감지(text_detection)
- 필기 입력 감지(document_text_detection)
- 자르기 힌트 감지(crop_hints)
- 얼굴 감지(face_detection)
- 이미지 속성 감지(image_properties)
- 라벨 감지(label_deetection)
- 특징 감지(landmark_detection)
- 로고 감지(logo_detection)
- 여러 객체 감지(object_localization)
- 유해성 컨텐츠 감지(safe_search_detection)
- 웹 항목 및 페이지 감지(web_detection)
위와 같은 기술을 지원하고, 그 중에서 광학 문자 인식(OCR) 기술이 Tesseract-OCR하고 비교할 만한 기술로 볼 수 있습니다.
일반적으로 Vision API에 대한 이미지 처리는 이미지 데이터를 request로 받으면 이에 대한 response를 JSON 형태의 데이터로 반환하도록 구성되어 있으며, REST Framework를 많이 사용합니다. 하지만 그 외에도 C#, GO, Java, Node.js, PHP, Python, Ruby 언어도 지원하니 이 부분도 참고하면 되겠습니다.
두 가지 다 오픈소스로 개발되었기 때문에 Github에 가면 각각 관련된 자료를 받을 수 있지만, 이 부분은 그냥 참고 정도로만 알아두시면 될 것 같고요. 과연 두 가지 API를 사용했을 때 어떤 결과로 텍스트를 추출하는 지를 궁금해 할 수 있으므로 이에 대한 결과만 간단히 보여드리도록 하겠습니다.
Text 추출
앞서 언급한 두 가지 OCR API 설치 방법은 생략하겠습니다. 설치 및 설정하는 방법까지 다루려면 별도의 글에서 다루는 것이 맞을 것 같으므로 양해 바랍니다. 필요하다면 별도의 글로 추가로 올리도록 하겠습니다. 그러므로 이 게시물에서는 모두 설치되어 있다는 것을 전제로 하겠습니다.
첫 번째 이미지 추출 예제

출처는 달빛조각사 몬스터 도감 내 텍스트 이미지입니다.
- 먼저 Google API로 추출한 결과입니다.
평원의 먹이사슬에서 높은 위치를 차지한 동물입니다. 강한\n턱 힘으로 위협이 되는 대상을 사정없이 물어뜯습니다. 이완벽하게 추출한 것 같지만 뭔가 옥의 티가 있죠? 맨 끝에 “이”라는 글자가 추출된 것으로 보아 사족이 들어간 듯 싶습니다.
- 다음은 Pytesseract (Tesseract-OCR의 Python Library)로 추출한 결과입니다.
평 원 의 먹 이 사 슬 에 서 높 은 위 치 를 차 지 한 동 물 입 니 다 . 강 한\n턱 힘 으 로 위 협 이 되 는 대 상 을 사 정 없 이 물 어 뜰 습 니 다 .정말 정직하게 추출됩니다.
두 가지 모두 제대로 검출을 했지만, Tesseract는 띄워쓰기 추출은 안 된 것을 확인할 수 있습니다.
두 번째 이미지 추출 예제
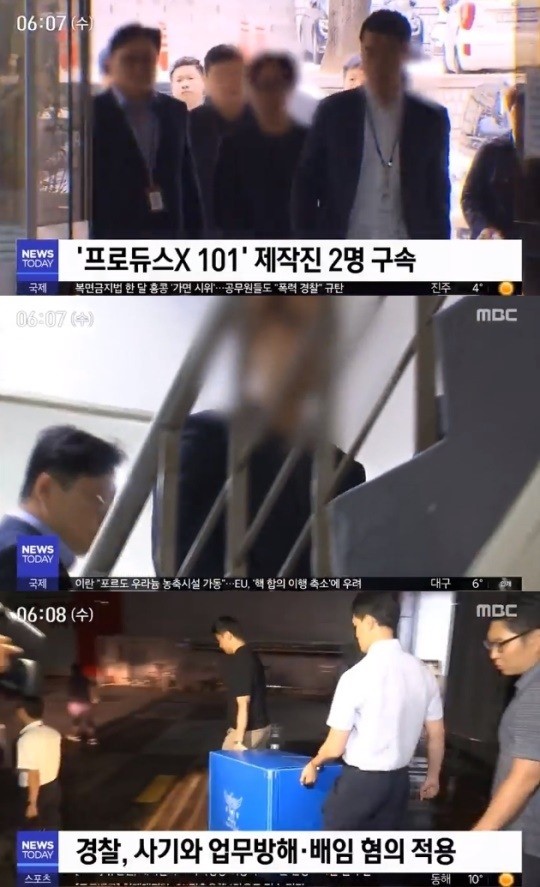
출처는 뉴스 기사의 이미지입니다.
- Google API 추출 결과
06:07 (수)\n9 \'프로듀스X 101\' 제작진 2명 구속\n국제\n복면금지법 한 달 홍콩 가면 시위…공무원들도 \'폭력 경찰 규탄\n진주\n106207 (수)\nMBC\nNEWS\nTODAY\n국제\n이란 "포르도 우라늄 농축시설 가동"….EU, \'핵 합의 이행 축소\'에 우려\n대구\n6\nMBC\n| 06:08 (수)\nNEWS\nTODAY\n2경찰, 사기와 업무방해·배임 혐의 적용\n스포츠\n동해\n106부분 부분 추출을 한 것을 알 수 있습니다. 100% 완벽한 검출은 아니지만 어느 정도의 신뢰도는 높은 것으로 확인됩니다.
- Pytesseract 추출 결과
pytesseract.pytesseract.TesseractError: (-11, "read_params_file: Can't open txt read_params_file: Can't open txt Tesseract Open Source OCR Engine v4.0.0-beta.1 with Leptonica Warning. Invalid resolution 0 dpi. Using 70 instead. Estimating resolution as 245 contains_unichar_id(unichar_id):Error:Assert failed:in file ../ccutil/unicharset.h, line 513")에러가 발생하네요. 뭔가 아쉽습니다.
세 번째 이미지 추출 예제

출처는 Yahoo.com 메인화면 이미지 캡쳐한 내용입니다.
- Google API 추출 결과
Leaked video reveals\npressure killed Epstein\nstory\nIn a leaked video released Tuesday, ABC News\nanchor Amy Robach said the network killed her\nstory on wealthy pedophile Jeffrey Epstein\nunder pressure from the British royal family.\n'It was unbelievable what we had' >>\n5914 people reacting한글보다는 영어가 아무래도 깔끔하게 추출되는 것으로 볼 수 있습니다. 검출 결과도 깔끔합니다.
- Pytesseract 추출 결과
Leaked video reveals\npressure Kkilled Epstein\ntu\n\nlnaigxdvMavilenwd dm﹒A9Caw 내\n松 내\n志\numimpmaausiuniuspnhhiaiamy\nL t 알 애\n\n| 배상당히 아쉬운 결과로 추출이 된 것을 확인할 수 있습니다. 아무래도 많은 보완이 필요할 것 같아 보이네요.
이상 Vision API와 Tesseract-OCR을 Python 언어 기반에서 수행한 테스트를 마치겠습니다.
테스트 결과는 Vision API의 압승이네요. 물론 3개 이미지만 가지고 단순 테스트를 한 것이라 어디가 더 낫다고 판단하기는 어렵습니다만, 일단은 이 정도로 파악이 됩니다. 다만 이러한 결과가 Tesseract-OCR이 별로다라고 판단은 할 수 없는것이 Python 언어 기반의 API를 가지고 테스트한 것이기 때문에 만약 다른 프로그래밍 언어와 다른 이미지를 사용한다면 결과는 또 다르게 나타날 가능성도 있습니다.
하지만 그럼에도 불구하고 Google Vision API의 이미지 텍스트 추출이 더욱 낫다고 추정할 수 있는 근거는 역시 딥러닝 기술을 활용한 학습을 통해서 이미지 추출 능력을 더욱 발전시켜나갈 수 있기 때문이겠죠.
OCR 기술은 옛날에는 단순히 이미지 내에서 음영이나 색상 등을 기반으로 추출하고 각 언어 별 형태소나 단어, 글자 등을 기반으로 추출하는 것에 그쳤다면, 최근에는 반복적으로 추출된 데이터를 바탕으로 딥러닝 기술을 활용하여 스스로 학습할 수 있도록 하고 있습니다. 이러한 학습 능력은 비단 OCR에만 그치는 것이 아니라 다른 기술에도 마찬가지로 적용되겠죠.
어떻게 해야 잘 추출하는가는 분명히 중요한 문제입니다만, 얼마나 많이 추출해서 신뢰도를 높이느냐는 더욱 중요한 문제가 될 수 있습니다. 그리고 얼마나 많이 해서 신뢰도를 높이는가. 그것이 머신러닝이 지향해야 할 목표이기도 하고요. 딥러닝 위주의 연구가 본격화된다면 아마 저도 이러한 부분에서 산출물을 만들어낼 수 있을 것으로 생각됩니다. 그 때는 더욱 좋은 글로 찾아뵐 수 있도록 하겠습니다.
이상 글 마치겠습니다.